


1.2 GB/sec Throughput: How Atlassian Scales ETL Pipelines
Achieving 1.2 Million Entities Per Second with Ephemeral and Self-Hosted Architecture

TL;DR
Situation
Atlassian needed to transfer large amounts of data between systems for tasks like server-to-cloud migrations and scheduled backups. Traditional ETL systems, which are always active, didn't fit their needs because they required data pipelines that could be set up and taken down quickly.
Task
Develop a platform capable of creating temporary (ephemeral) data pipelines that can be provisioned at runtime to handle user-initiated data movements and scheduled tasks efficiently.
Action
Atlassian built the Lithium Platform, an advanced ETL system with unique features:
Dynamic and Ephemeral Pipelines: Lithium's data pipelines, called Workplans, are created on-the-fly for specific data movement tasks and are decommissioned once the task is completed.
Bring Your Own Host (BYOH) Model: Lithium allows different services within Atlassian to host their own data processors by integrating the Lithium SDK. This approach ensures that data processing occurs close to the relevant data and business logic, enhancing efficiency.
Pipeline Isolation: Each Workplan operates independently with its own set of Kafka topics and processors, ensuring that data remains isolated and secure. This setup also supports features like pausing, resuming, and rewinding data pipelines without affecting others.
Result
The Lithium platform demonstrated scalability, moving 500 GB of data across 100 Workplans in just 7 minutes, achieving a throughput of 1.2 GB/sec.
Use Cases
Cloud Migrations, Compliance and Data Archiving, Data Synchronization, Backup and Restore Operations
Tech Stack/Framework
Apache Kafka, Kafka Streams, Java
Explained Further
Lithium: Elevating ETL with Ephemeral and Self-Hosted Pipelines
At Atlassian, transferring large amounts of data across systems is a common requirement. Whether it’s for migrations, scheduled backups, or real-time data processing, these use cases demand a robust and flexible data pipeline. However, traditional ETL (Extract, Transform, Load) systems, which are long-lived and continuously running, weren’t suitable for Atlassian’s dynamic requirements. To address this, the Lithium Platform was developed—an ETL++ platform that introduces dynamic and ephemeral pipelines, offering capabilities that go beyond traditional ETL systems.
Why Dynamic Pipelines Are Necessary
Lithium was designed to handle specific, runtime-dependent requirements that traditional ETL systems cannot accommodate:
Migrations (Server-to-Cloud or Cloud-to-Cloud): These are user-initiated, requiring pipelines to be provisioned when a migration begins and decommissioned immediately after completion.
Scheduled Backups: Backup pipelines are triggered at fixed intervals and must terminate after completing the operation to avoid unnecessary resource usage.
Proximity to Service Context: Embedding stream processors within services ensures access to data and domain logic, meeting functional requirements while maintaining performance.
Distributed Coordination: With sources, transformations, and sinks often spread across multiple systems, the platform needs to handle cross-service coordination seamlessly.
To meet these requirements, Atlassian built Lithium, a 100% event-driven platform based on Apache Kafka and Kafka Streams.
Workplans: Dynamic and Ephemeral Pipelines
In Lithium, data pipelines are called Workplans. A Workplan encapsulates all the components required to run a pipeline—source, transform, and sink. Workplans are dynamically provisioned when a task begins and decommissioned upon completion, making them ephemeral and resource-efficient.
Anatomy of a Workplan
Each Workplan consists of three core processor types:
Source (Extract): Reads data from the source system and feeds it into the pipeline.
Transform: Validates and modifies the data to prepare it for the target system.
Sink (Load): Writes the processed data to its final destination.
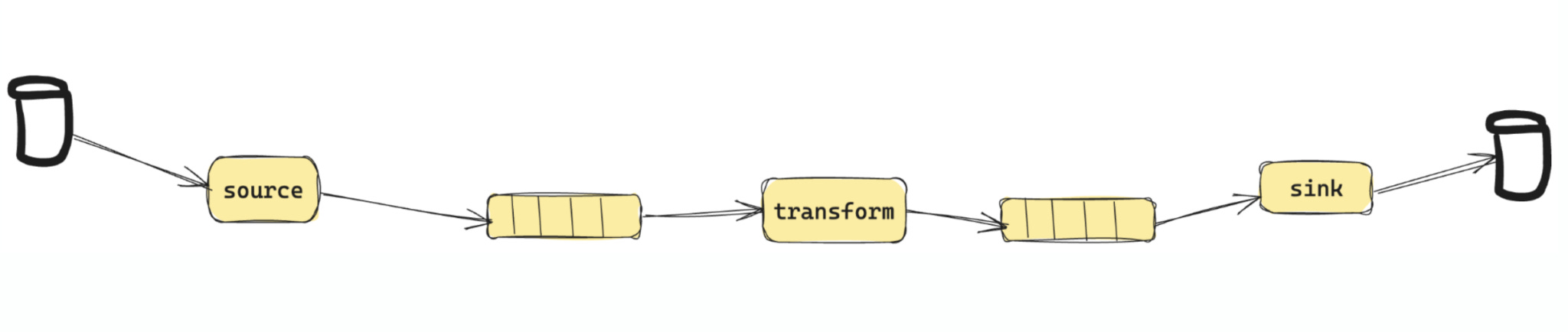
Everything in yellow in the above diagram is dynamically provisioned and ephemeral including the Source, Transform, Sink, and the Kafka topics between them. But how are these workplan processors hosted?
Bring Your Own Host (BYOH) Model
Lithium’s BYOH model allows consumers, such as Jira or Confluence teams, to host and manage their own processors. These processors, built using the Lithium SDK, are integrated into the services that require data movement. The SDK abstracts Kafka complexities like topic creation, authentication, and data streaming, enabling teams to focus on custom processing logic.
This approach provides significant advantages:
Proximity to Data: Processors are located closer to the data source and domain logic, reducing latency and improving throughput.
Flexibility: Teams can implement tailored processing logic while leveraging Lithium’s infrastructure.
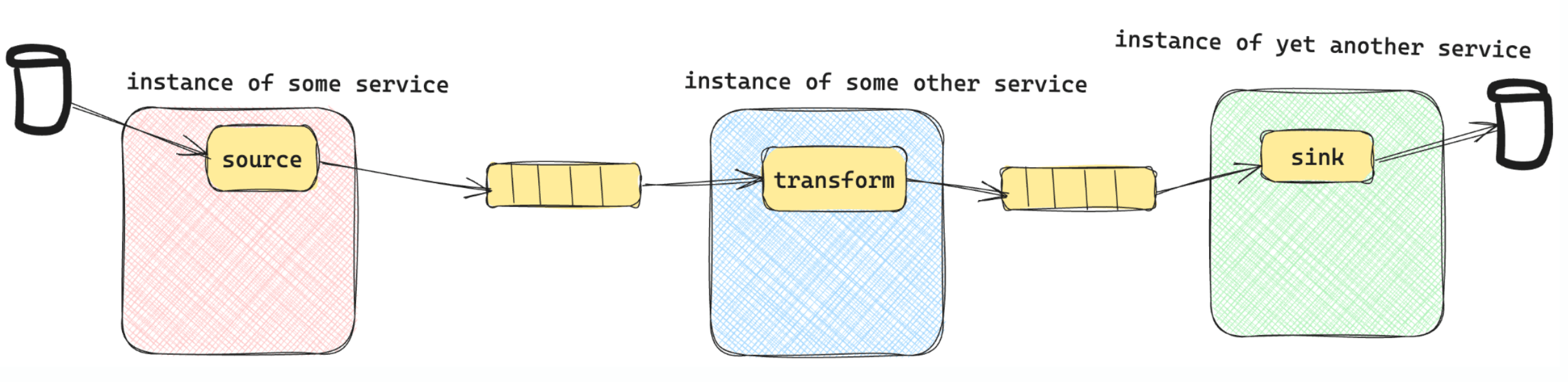
Pipeline Isolation
Lithium ensures complete isolation for every Workplan. Each pipeline operates independently, with dedicated Kafka topics, processors, and runtime configurations. This design guarantees:
Tenant-Level Data Segregation: Ensures data for each tenant is securely isolated.
Advanced Features: Capabilities like pausing, resuming, rewinding, and remediation can be executed on individual pipelines without affecting others.
Control Plane and Data Plane
Lithium is divided into two logical components:
Control Plane: The platform’s brain, responsible for managing Workplans, provisioning resources, and coordinating Kafka topics.
Data Plane: Executes the data movement tasks using processors provisioned in the services integrating with Lithium.
The planes communicate through Kafka topics, ensuring seamless orchestration between control and execution.
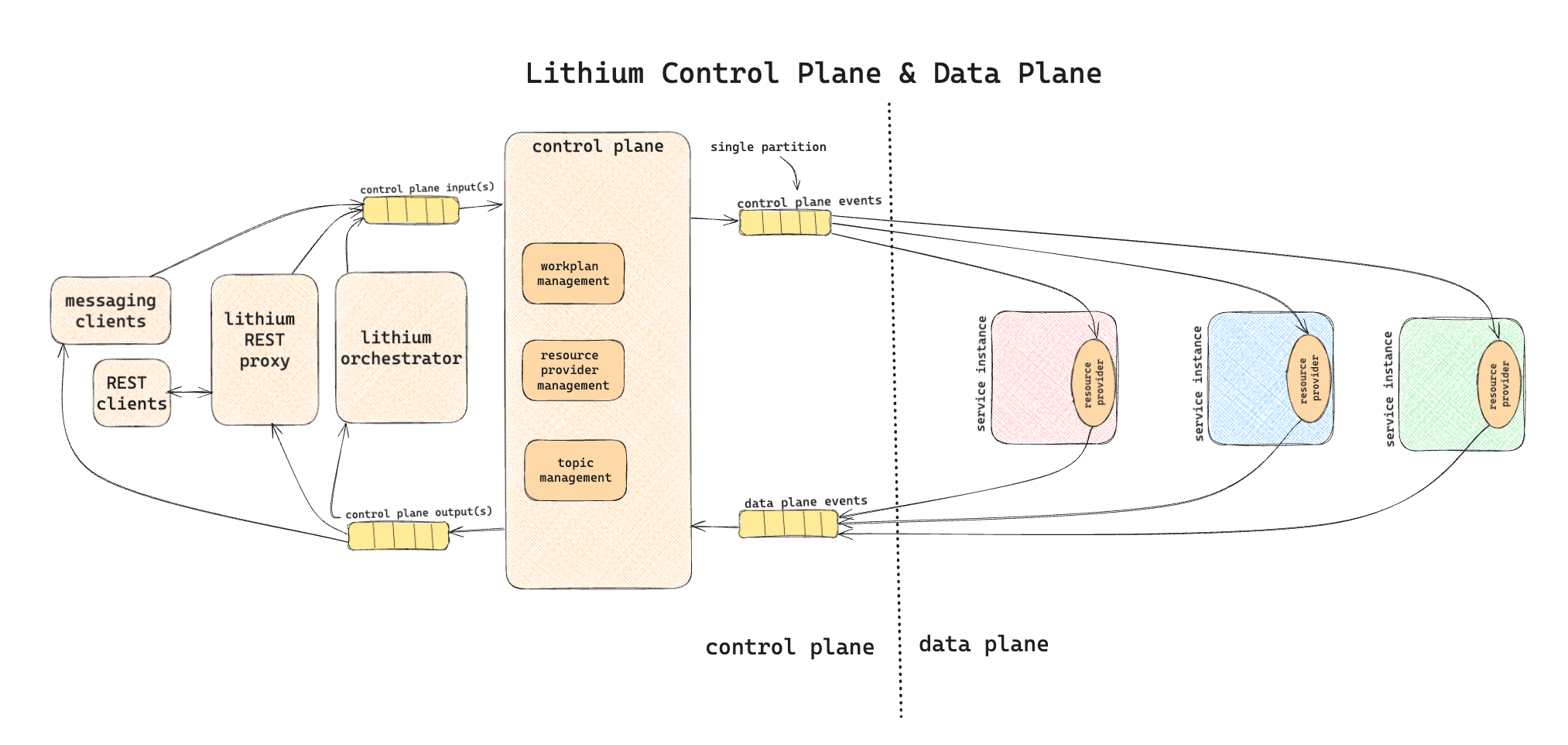
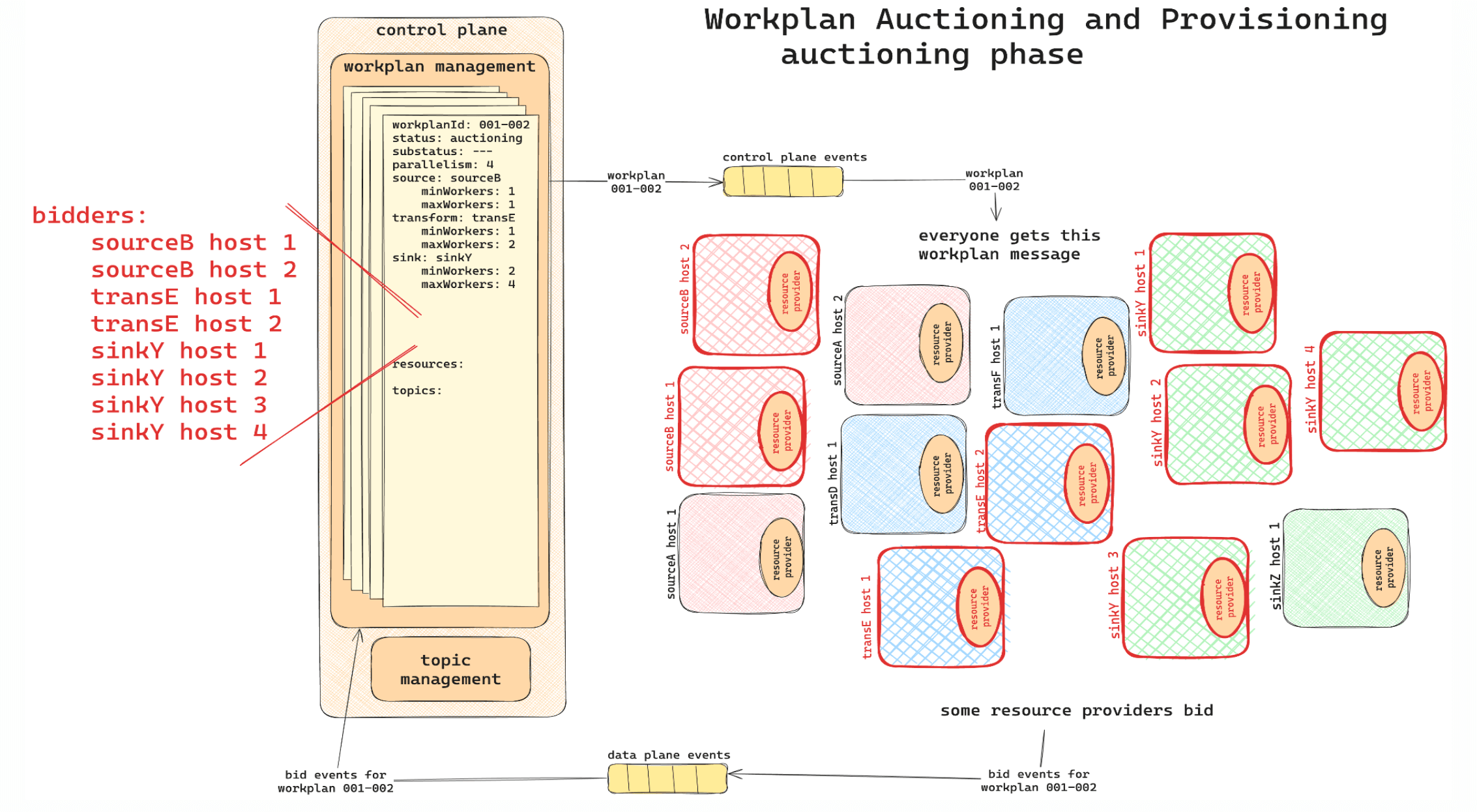
Workplan Auctioning
When a Workplan is created, resource providers (service hosts) bid to participate in its execution. The control plane evaluates these bids and assigns resources based on capacity and relevance. This auctioning process ensures optimal resource utilization and scales efficiently to meet demand.
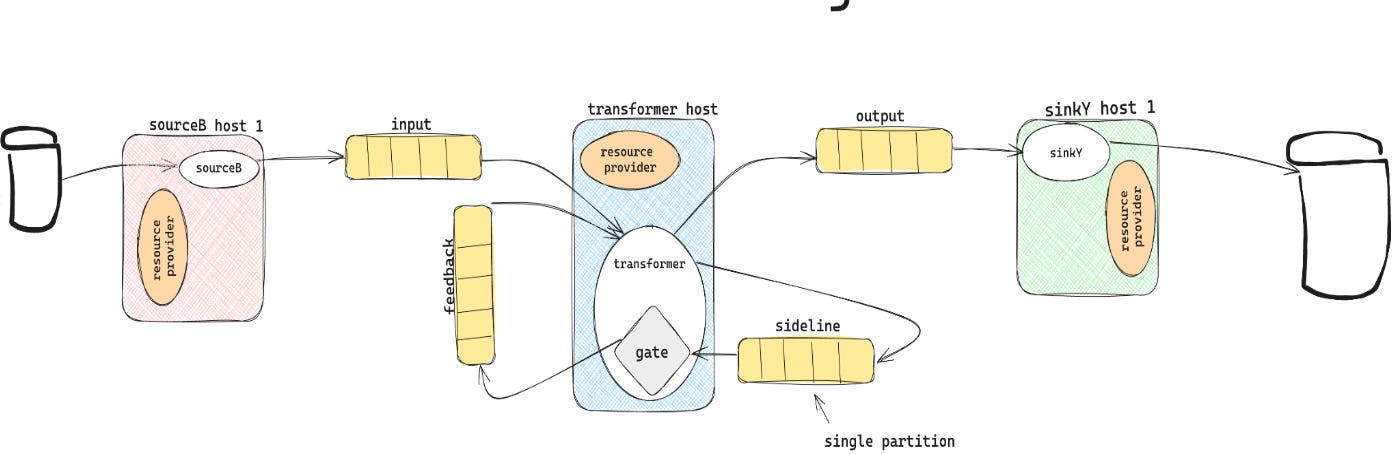
Sidelining and Remediation
Data Sidelining is a process where data that fails validation is diverted to a dedicated sideline topic within a Workplan, while valid data continues downstream. The sideline topic is controlled by a gate, implemented using Kafka stream topology, which remains closed to hold the failed data. If the number of failed entities exceeds a predefined threshold in the Workplan specification, the Control Plane halts the pipeline, pausing all processors.
In-Progress Remediation allows users to inspect and address these validation failures without permanently stopping the pipeline. Users can introduce new transformations to the active Workplan, dynamically updating the processing chain. This update reconfigures the pipeline, opening the feedback gate to allow both sidelined and new data to resume processing using the revised transformations. This feature ensures efficient error handling while minimizing disruptions to the pipeline’s operation.
Advanced Capabilities
The platform has a couple of advanced functionalities:
Rewinding: The platform retains extracted data in an ingress topic, enabling pipelines to restart from a specific point without re-extracting data.
Multiple Transformers: Workplans support chains of transformers, allowing complex data transformations across different services.
Multiple Sinks: Data can be sent to multiple sinks simultaneously, supporting diverse processing needs within a single pipeline.
Performance and Scalability
Lithium has been tested to ensure it meets Atlassian’s scale and performance demands. Key results from production tests include:
Throughput: ~1.2 million entities per second (~1.2 GB/sec).
Data Volume: 500 million entities (500 GB) processed in 7 minutes.
Parallel Workplans: 100 concurrent pipelines, each handling 5 million entities.
Lessons Learned
Dynamic Scalability: Building ephemeral pipelines allowed Atlassian to scale operations dynamically, efficiently managing large datasets with minimal overhead.
Proximity to Data: Hosting processors closer to business logic improved throughput and reduced latency.
Isolation and Observability: Tenant-level pipeline isolation enabled advanced monitoring, debugging, and resilience capabilities.
Streamlined Collaboration: Abstracting Kafka complexities with the Lithium SDK empowered teams to focus on custom processing needs, fostering seamless integration.
The Full Scoop
To learn more about the update, check the Atlassian Blog post on this topic.