


China Strikes Again, Sesame's Human-Like Voice and OpenAI's $20K PhD Bot
Catch up on Google’s Data Science Agent, DoorDash's deep learning fixes and Datadog's Kafka reliability at scale

Fellow Tinkerers!
Time for another round-up of noteworthy AI/Data stuff happening. As always, look forward to your feedback or suggestions. Feel free to reply to this email or leave a comment below. Now without further ado, let’s get to it!
The Buzz 🐝
Another Chinese AI company has struck again with Manus unveiling its general agent a couple of days ago. While many of the early reviews have been positive, some users have highlighted its limitations, mentioning this is not a second ‘DeepSeek moment’
Sesame (no, not the children TV show) introduced their AI conversational model which sounds a lot like humans (and creeped out some users). I also obtained the footage of Elmo’s reaction after trying the demo

OpenAI is thinking about rolling out a ‘PhD-level’ AI Agent for a mere cost of 20,000 a month. Now for that price they better apply for grants, publish papers and secure funding to fund itself!
Data Science & AI
Google’s Data Science Agent in Colab
Google introduced their data science agent on Google Colab. You can prompt it to analyse data and share the results with your teammates

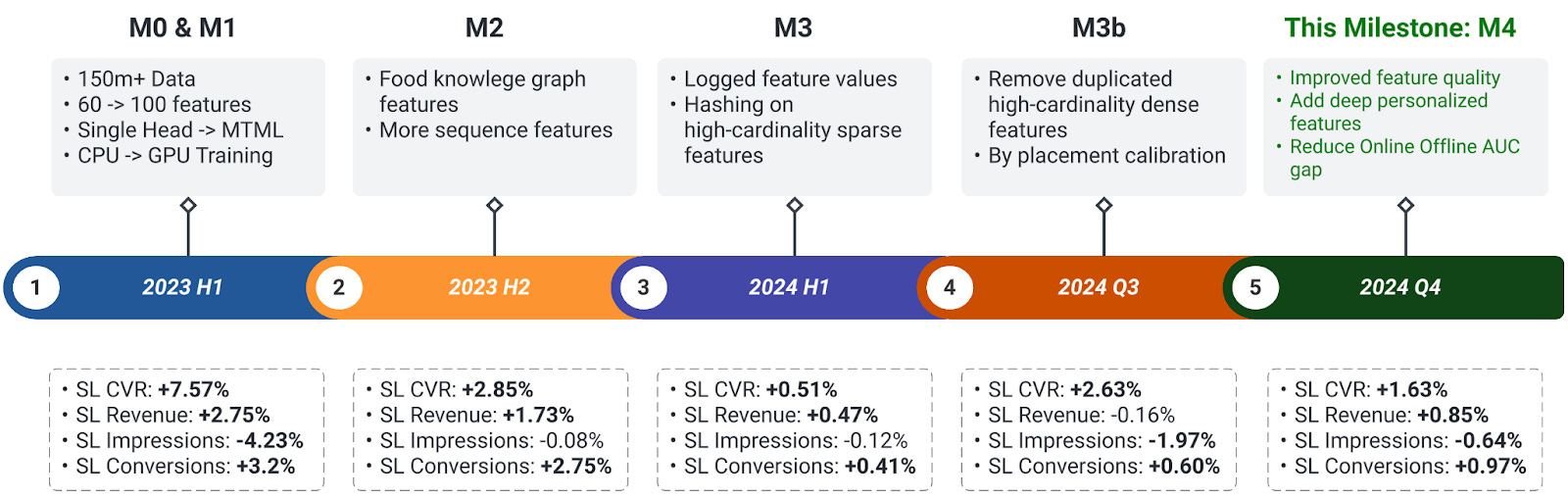
How to investigate the online vs offline performance for DNN models
Learn how DoorDash's Ads Quality ML team addressed performance discrepancies between offline evaluations and online inferences in their deep learning models by implementing a scalable debugging methodology, reducing the AUC gap from 4.3% to 0.76%.
Boosting A/B Testing Efficiency for 1M+ Users
Learn how Stripe rolled out A/B testing at scale for more than its 1 million users
Data & Analytics Engineering
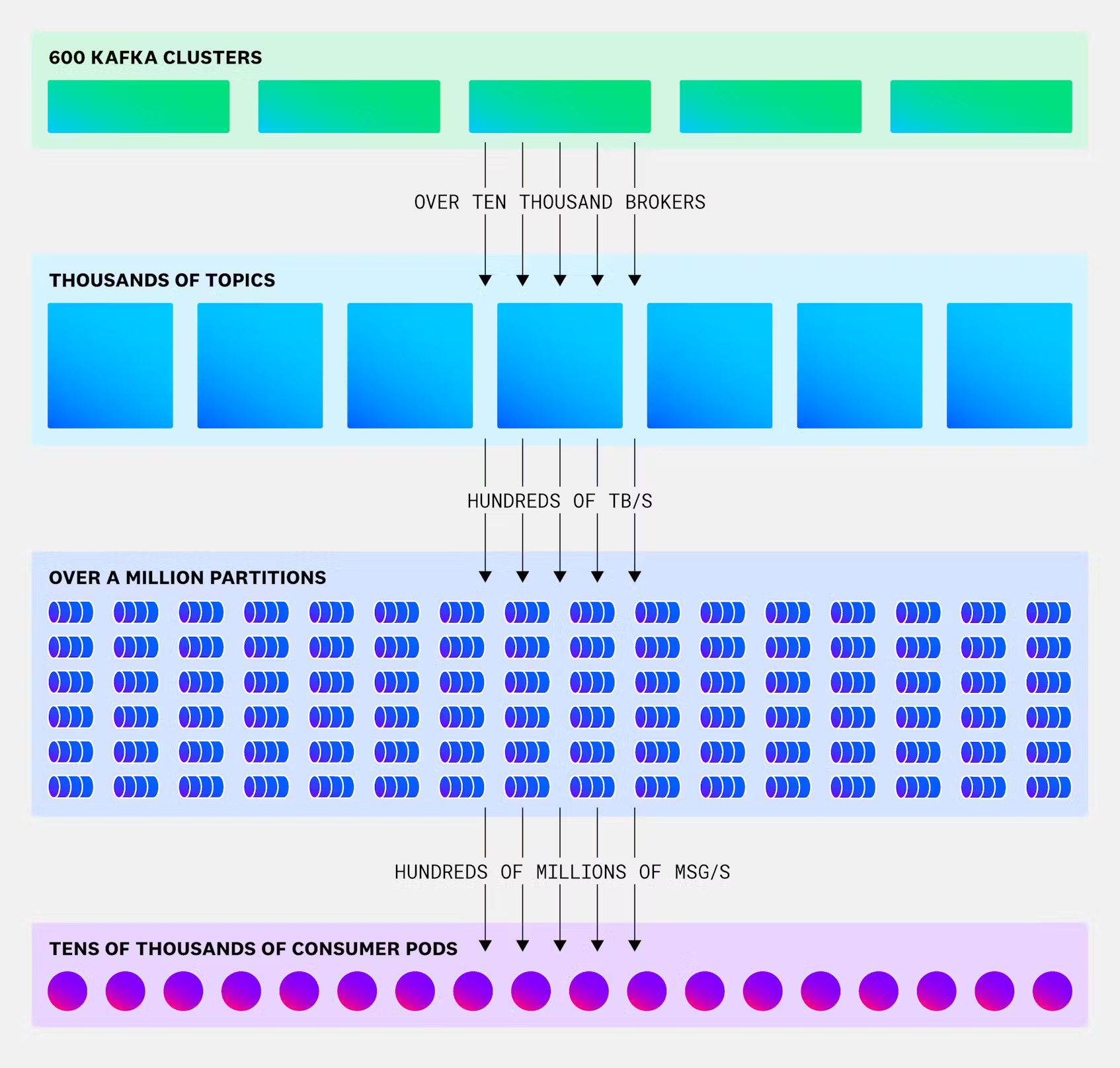
Achieving relentless Kafka reliability at scale with the Streaming Platform
Discover how Datadog enhanced Kafka reliability at scale by developing a Streaming Platform that decouples producers and consumers from specific clusters, enabling real-time traffic failovers and dynamic workload balancing.
Building Trust in Data: The Fundamentals of Data Quality
provides a good overview of basic quality checks that need to be considered and implemented
1.2 GB/sec Throughput: How Atlassian Scales ETL Pipelines
Discover how Atlassian scales its ETL pipelines to run 100 pipelines concurrently
Data Analysis and Vizualisation
Numbers Don’t Tell the Whole Story: The McNamara Fallacy
How just focusing on quantitative data can lead you down the wrong path
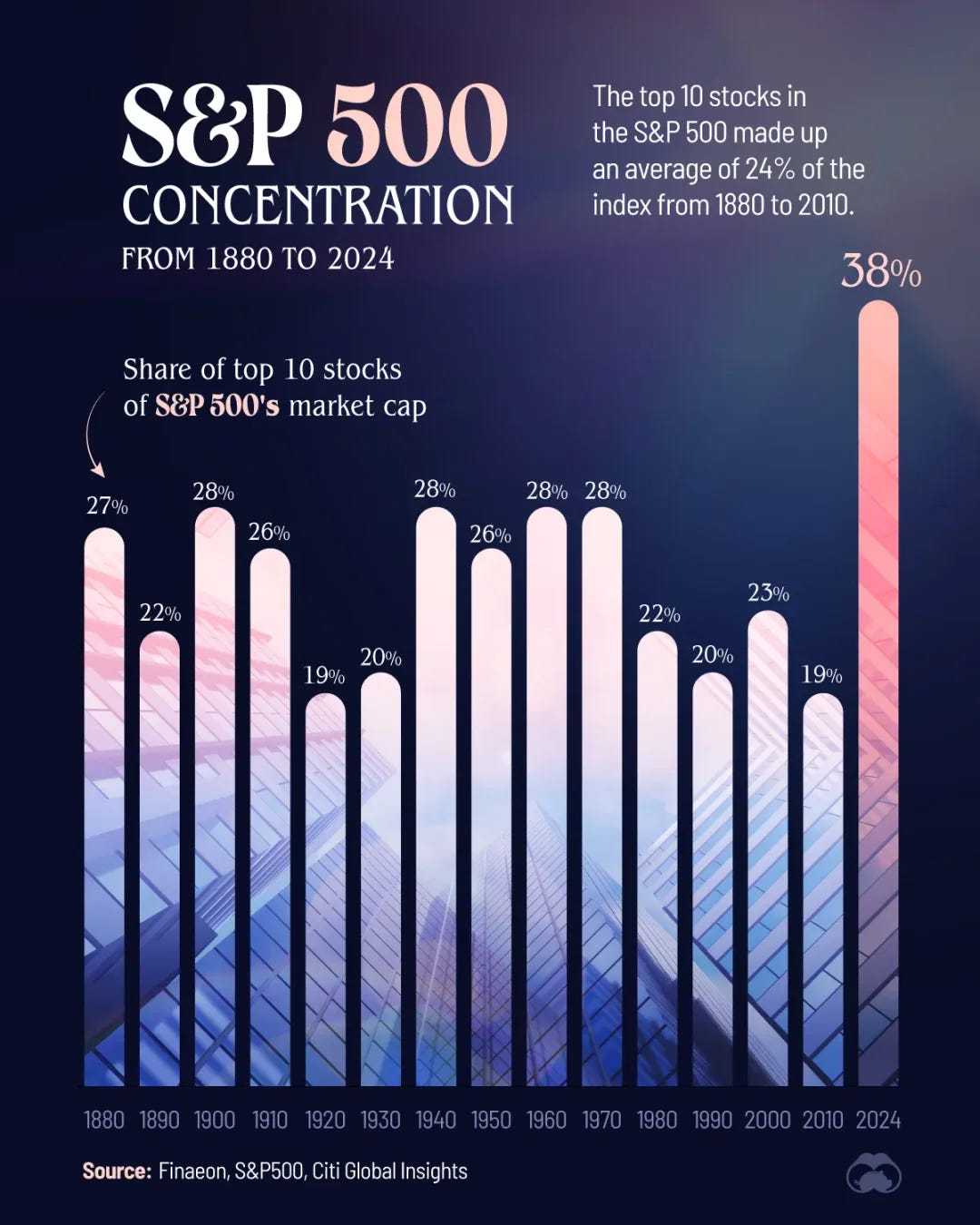
The S&P 500 Is Getting More Concentrated
Interesting visualisation of S&P top 10 stocks concentration
Happy Ending
SQL explained in one image

Thank you for mentioning our post 🙏💐