

Cracking the ETA Code: How Lyft Improves its Predictions
Minimizing rider frustration with more accurate arrival estimates


TL;DR
Situation
Lyft aimed to enhance the accuracy of its pre-ride Estimated Time of Arrival (ETA) predictions to improve rider satisfaction and reduce cancellation rates. Challenges included unpredictable driver availability, traffic conditions, and marketplace dynamics.
Task
The objective was to develop a machine learning model capable of providing reliable ETA predictions before a ride is requested, accounting for various uncertainties inherent in ridesharing.
Action
Lyft's engineering team implemented the following steps:
Data Collection: Gathered extensive historical and real-time data, including driver availability, traffic patterns, and rider behavior.
Feature Engineering: Identified key factors influencing ETA reliability, such as driver preferences, traffic conditions, and supply-demand dynamics.
Model Development: Built a tree-based predictive model that estimates the likelihood of a driver arriving within a reasonable timeframe of the pre-requested ETA.
Validation and Testing: Conducted simulations to assess the model's accuracy and its impact on rider cancellation rates, ensuring the predictions aligned with real-world scenarios.
Result
The implementation of this machine learning model leads to more accurate pre-ride ETA predictions
Use Cases
ETA Prediction, Rider Cancellation Reduction, Resource Allocation Improvement
Tech Stack/Framework
Gradient Boosting Tree Models, LyftLearn, S3 Storage, Apache Hive
Explained Further
Improving ETA Reliability
The reliability of Estimated Time of Arrival (ETA) predictions in ridesharing is not just about providing riders with a number—it’s a culmination of machine learning (ML) models and a deep understanding of the dynamic marketplace environment. At Lyft, the approach to ETA reliability focuses on pre-ride predictions, aiming to address rider concerns and reduce cancellations through data-driven decision-making. Here's a closer look at the methods and innovations employed.
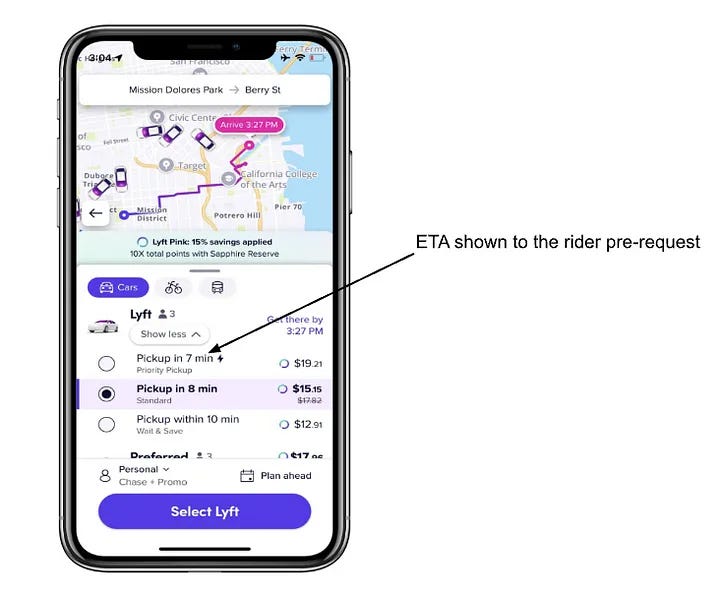
The Core Challenge: Unpredictability in the Marketplace
ETA predictions before a ride is requested are complex due to multiple uncertainties:
Driver Availability: Factors such as driver preferences, contention (multiple riders competing for the same driver), and status changes (e.g., logging off unexpectedly) affect matching reliability.
Dynamic Conditions: Traffic fluctuations, GPS inaccuracies, and navigation detours can skew ETAs.
Marketplace Dynamics: Variations in supply and demand within specific neighborhoods, which can change within minutes, further complicate accurate predictions.
Addressing these uncertainties requires harnessing real-time data and historical patterns to create a robust system capable of adapting to evolving conditions.
ML to the Rescue
To enhance ETA reliability, Lyft developed a classification model using gradient boosting tree-based techniques. These models are particularly effective for structured tabular data, offering:
Interpretability: Easier understanding of feature contributions.
Efficiency: Lower computational requirements compared to deep learning.
Robustness: Strong performance with smaller datasets, outliers, and missing values.
Feature Engineering
Features are the backbone of any ML model, and Lyft incorporated a rich set of features to capture marketplace uncertainty:
Driver Data:
Characteristics of nearby available drivers, including estimated driving time, distance, and online/offline status, help assess the likelihood of matching with a rider.
Historical Insights:
Aggregated data on past driver ETAs, match times, and ride completion rates at the geohash level provide performance benchmarks.
Marketplace Indicators:
Real-time data on app opens, unassigned rides, and driver pool counts gauge supply-demand imbalances.
Temporal and Spatial Data:
Factors like time of day, location-specific trends, and ride types add granularity to predictions.
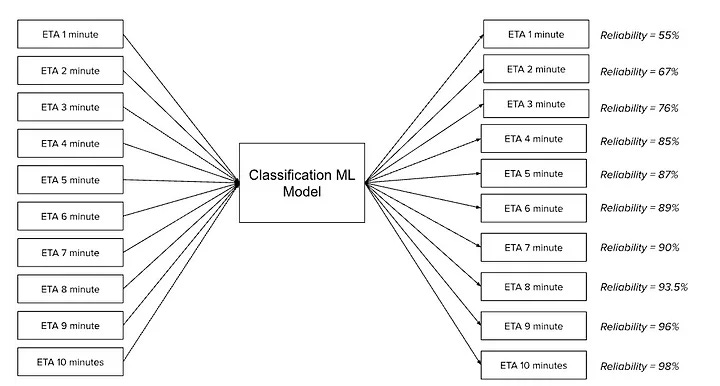
By combining these features, the model can predict the likelihood of driver arrival within a specified ETA bracket, ensuring the reliability of the estimates presented to riders.
Labeling Strategy
Lyft’s model generates binary labels for ETA reliability by comparing the actual request-to-driver arrival time with the predicted ETA. Reliability is defined as a driver arriving within an acceptable timeframe of the estimated arrival.
Training on All Possible ETA Estimates
Instead of using only factual ETAs shown to riders, Lyft duplicates training data across all possible ETA brackets (e.g., 1–10 minutes). This ensures the model is exposed to a full range of scenarios. The key advantages of this method are
Avoiding Feedback Loops: Training solely on factuals risks degrading model performance over time.
Equal Representation: All ETA brackets are represented equally, improving predictions for less common scenarios.
Handling Variances: The model learns to accommodate inaccuracies in upstream driver ETA predictions.
This approach improves the model’s robustness, ensuring accurate and reliable predictions across diverse real-world conditions.
Model Evaluation and Continuous Monitoring
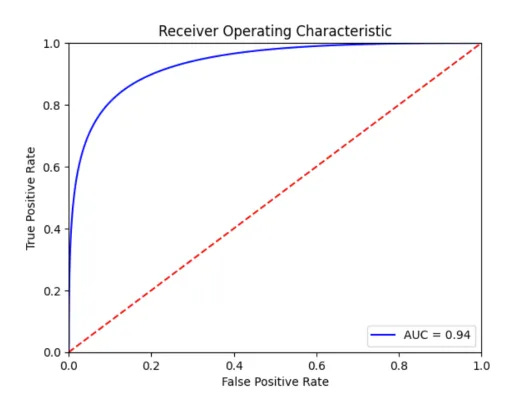
Lyft uses Area Under the Curve (AUC) as the primary evaluation metric. This approach ensures reliability across all thresholds, rather than focusing on a single one. Additionally, the team assesses performance per ETA bracket to identify biases, especially for longer ETAs, which tend to have less data representation.
Beyond initial deployment, maintaining model performance in a dynamic environment is a significant challenge. Factors such as shifting commuting patterns or app updates can degrade model accuracy. To address this:
Automated Retraining Pipelines: Leveraging LyftLearn, Lyft establishes continuous monitoring systems to detect data drifts and automate retraining processes.
Drift Detection Alarms: These systems identify feature changes that may impact predictions, enabling swift responses to maintain reliability.
Lessons Learned
Understanding Real-World Variability is Key
ETA accuracy relies on addressing complex, unpredictable variables such as driver availability, traffic patterns, and marketplace dynamics.Comprehensive Training Mitigates Bias
Training models across all possible ETA scenarios prevents feedback loops and ensures consistent performance for both common and rare cases.Continuous Monitoring Sustains Performance
The dynamic nature of ridesharing necessitates ongoing performance monitoring and retraining.Cross-Team Collaboration Enhances Success
Collaboration between teams ensures the alignment of data insights, UX requirements, and technical implementation, leading to better solutions.
The Full Scoop
To learn more about the update, check the Lyft Blog post on this topic.