

From Pins to Personalization: Inside Pinterest's Retrieval System for 500 Million Users
Understand the challenges and solutions in delivering personalized content to Pinterest's massive community.


TL;DR
Situation
Pinterest's existing content retrieval system relied on traditional methods that couldn't fully capture the complex relationships between users and the vast array of content, leading to less personalized recommendations.
Task
Develop a scalable, embedding-based retrieval system capable of learning and representing the nuanced interactions between users and content, effectively processing Pinterest's extensive dataset.
Action
System Design: They designed an internal embedding-based retrieval system for organic content, utilizing advanced machine learning techniques to generate embeddings that position users and content within a shared vector space.
Data Processing: To train the model effectively, they processed large-scale data, extracting meaningful features from user interactions and content metadata, handling billions of data points to ensure accurate embeddings..
Model Training and Deployment: The model was trained on this extensive dataset, optimized for performance and relevance, and seamlessly integrated into Pinterest's infrastructure without disrupting user experience.
Result
Implementing the embedding-based retrieval system improved content relevance and user engagement on Pinterest, leading to more personalized recommendations and increased interaction rates.
Use Cases
Personalized Recommendation, Search Functionality
Tech Stack/Framework
Two-Tower Model, Approximate Nearest Neighbor, Auto Retraining
Explained Further
Content Discovery with Advanced Retrieval System
Modern recommendation systems often employ a multi-stage approach, where the retrieval stage selects a subset of relevant items from a vast pool, and the ranking stage orders these items based on predicted user engagement. Below is a general multi-stage recommendation system at Pinterest:
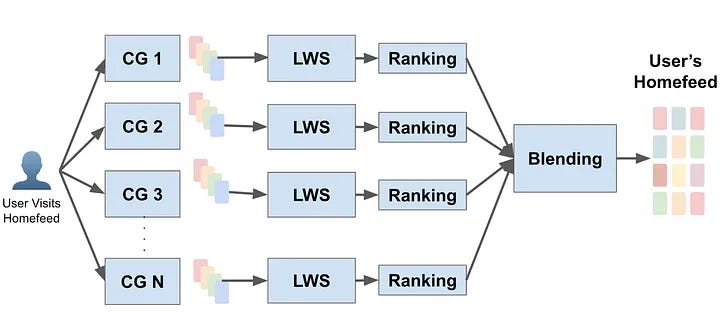
At Pinterest, the existing retrieval methods primarily relied on heuristic approaches, such as Pin-Board graphs or user-followed interests. Recognizing the limitations of these methods in capturing complex user-content relationships, Pinterest embarked on building an internal embedding-based retrieval system for organic content, learned purely from logged user engagement events. This system has been successfully deployed for features like Homefeed and notifications.
Power of Two-Tower Models for Personalized Recommendations
The core of this retrieval system is a two-tower model architecture, a design widely adopted in the industry for large-scale recommendation tasks. In this setup:
User Tower: Encodes user-specific features, including long-term engagement history, profile information, and contextual data.
Pin Tower: Encodes item-specific features, such as content metadata and visual attributes.
Both towers output embeddings that represent users and items in a shared vector space. The relevance between a user and an item is determined by the dot product of their embeddings. This architecture allows for efficient retrieval through nearest neighbor search, as item embeddings can be precomputed and stored, enabling rapid matching with user embeddings computed at request time.
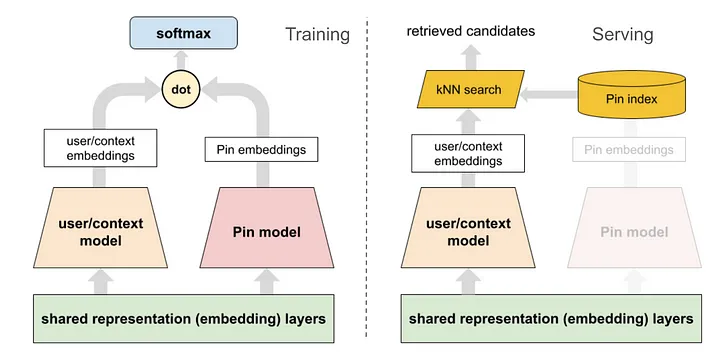
Training this model involves optimizing it as an extreme multi-class classification problem. Given the impracticality of performing a full softmax over the entire item corpus, Pinterest employs in-batch negative sampling. In this approach, each positive user-item interaction in a training batch is treated as a positive example, while other items in the batch serve as negative examples. To address potential popularity biases in the sampled negatives, the model incorporates a correction term based on the estimated probability of each item appearing in the batch:

Building a Scalable Infrastructure for Real-Time Personalization
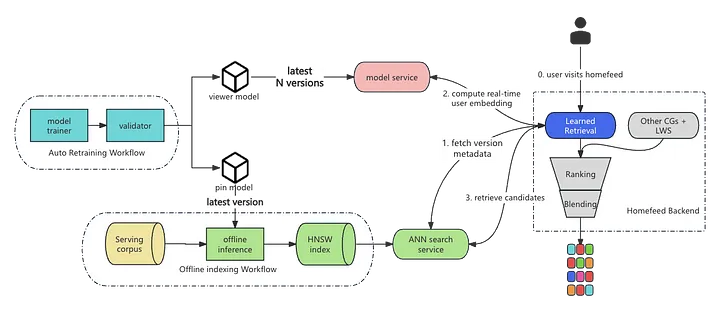
Serving over 500 million monthly active users requires a robust and scalable infrastructure. Pinterest's retrieval system comprises two main components:
Online Serving: User embeddings are computed in real-time during each request, leveraging the most recent features to ensure personalized retrieval.
Offline Indexing: Millions of item embeddings are precomputed and stored in Pinterest's in-house Approximate Nearest Neighbor (ANN) serving system, known as Manas. This setup allows for efficient retrieval by matching real-time user embeddings with the precomputed item embeddings.
Auto Retraining
User interests and content trends on Pinterest are dynamic, necessitating frequent model updates to maintain relevance. To address this, Pinterest has established an auto-retraining workflow that periodically retrains the models, validating performance before deployment. A critical aspect of this process is ensuring synchronization between the user and item embeddings. As the two-tower model results in separate artifacts for users and items, any update must ensure that both embeddings are aligned to prevent mismatches that could degrade recommendation quality. This is achieved by attaching model version metadata to each ANN search service host, ensuring that the homefeed backend retrieves and utilizes the correct model version during serving.
Results
Pinterest's Homefeed employs over 20 candidate generators to cater to diverse user engagement scenarios. The learned retrieval candidate generator, focusing on user engagement, has achieved top user coverage and ranks among the top three in save rates. Its success has led to the deprecation of two other generators, significantly enhancing overall site engagement.
Lessons Learned
Transitioning from Heuristic to Embedding-Based Retrieval: Shifting from traditional heuristic methods to an embedding-based approach, trained on user engagement data, significantly enhances content relevance and personalization.
Leveraging Two-Tower Model Architecture: Utilizing a two-tower model, which separately processes user and item features into a shared embedding space, enables efficient and scalable retrieval of personalized content.
Implementing Auto-Retraining Workflows: Establishing automated retraining processes ensures that models remain current with evolving user behaviors and content trends, maintaining recommendation accuracy over time.
Ensuring Synchronization in Model Deployment: Coordinating the deployment of user and item embeddings is crucial; misalignment can lead to degraded recommendation quality, highlighting the need for synchronized updates.
The Full Scoop
To learn more about the implementation, check Pinterest Blog post on this topic