


How Datadog Achieved 99% Timeout Reduction with 20x Scalability Boost
Discover the architecture that cut costs by 50% and unlocked massive scalability

TL;DR
Situation
Datadog's time-series database, designed in 2016, struggled to manage a 30x growth in data volume and rising query complexity, resulting in slower performance and higher maintenance overhead.
Task
Develop a scalable indexing system to efficiently process high-cardinality data while improving query speed and reducing operational costs.
Action
The team implemented an inverted index inspired by search engines, mapping tags to time-series IDs. Using RocksDB for storage, they ensured scalability, reliability, and efficient query filtering.
Result
Query performance improved by 99%, enabling support for 20x higher cardinality metrics, reducing query timeouts, and cutting operational costs by nearly 50%.
Use Cases
Real-Time Monitoring, Tag-Based Filtering, Dynamic Schema Handling, Query Execution
Tech Stack/Framework
RocksDB, Apache Kafka, SQLite, Time-Series Database, Rust
Explained Further
Understanding the Problem
Datadog’s timeseries database faced significant challenges as data volumes grew 30x between 2017 and 2022. The increasing complexity of user queries and higher data cardinality strained the existing indexing system, introduced in 2016. The original architecture became a bottleneck for query performance and required substantial maintenance.
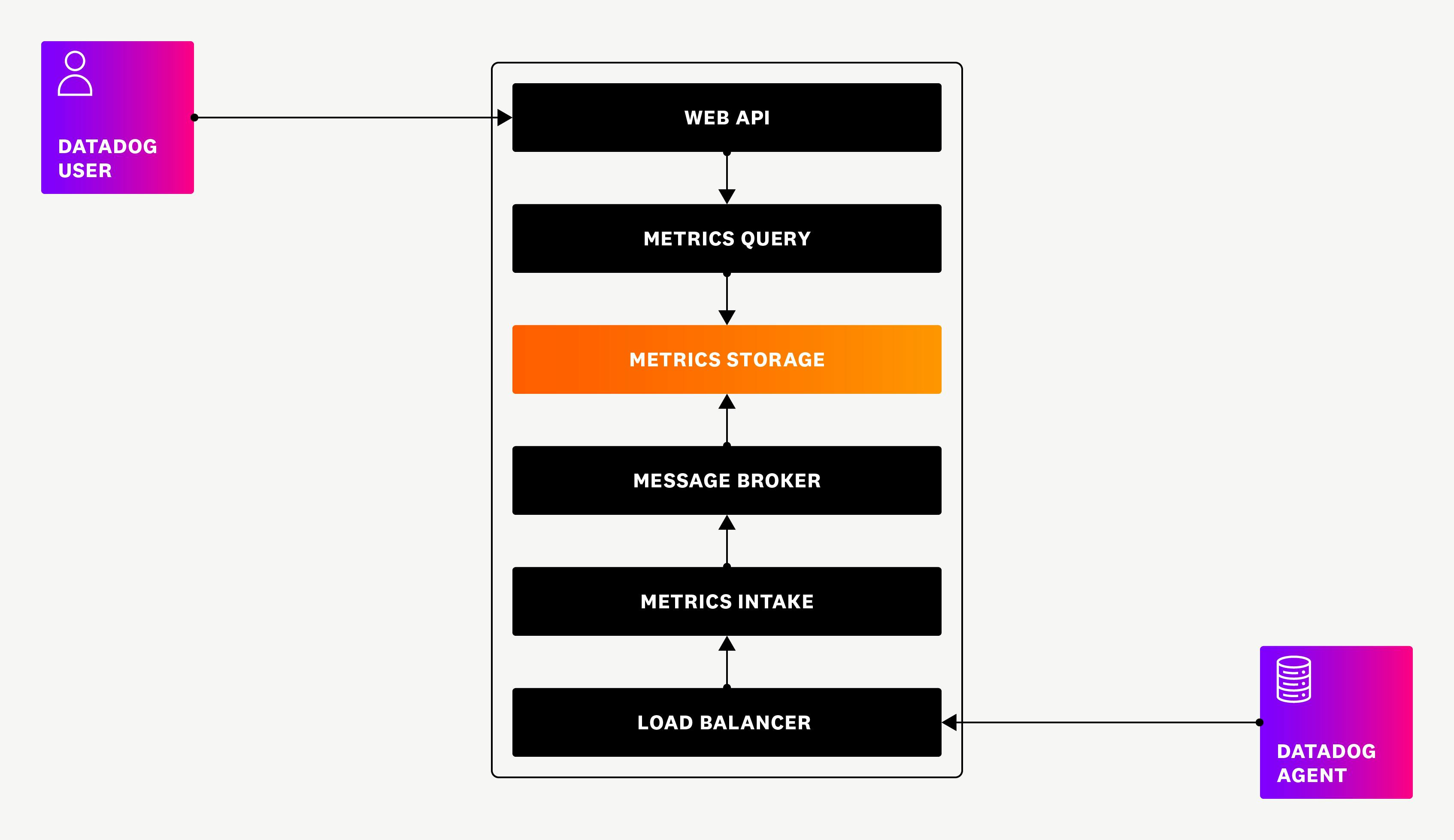
Metrics Platform Overview
The Datadog metrics platform is composed of three major components: intake, storage, and query.
Intake: Handles a stream of metrics data, including metric names, tags, timestamps, and values. The ingested data is sent to a message broker (Kafka) for processing and storage.
Storage: Consists of two services:
The Timeseries Database, which stores metric values, timestamps, and IDs.
The Timeseries Index, responsible for indexing tags associated with timeseries data.
Query: Connects to the storage layer to fetch and aggregate data based on user queries.
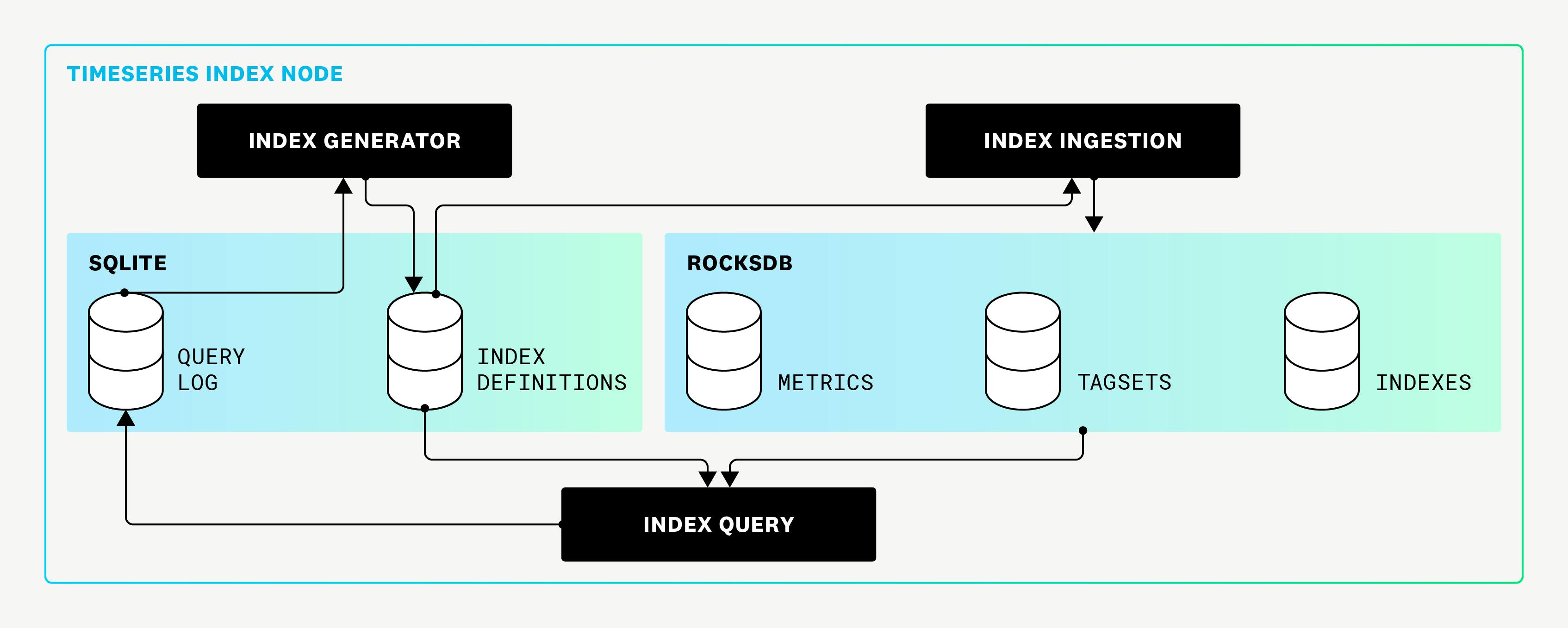
Original Indexing System
The first-generation indexing system relied on dynamically generated indexes. A background process analyzed the query logs, identifying resource-heavy queries to create new indexes. While effective for programmatic queries, this approach struggled with unpredictable, user-driven queries, leading to inconsistent performance.
The architecture used:
SQLite for storing metadata and query logs.
RocksDB for managing data writes and maintaining indexes.
However, this system required frequent manual intervention to maintain query efficiency, especially for high-cardinality workloads.
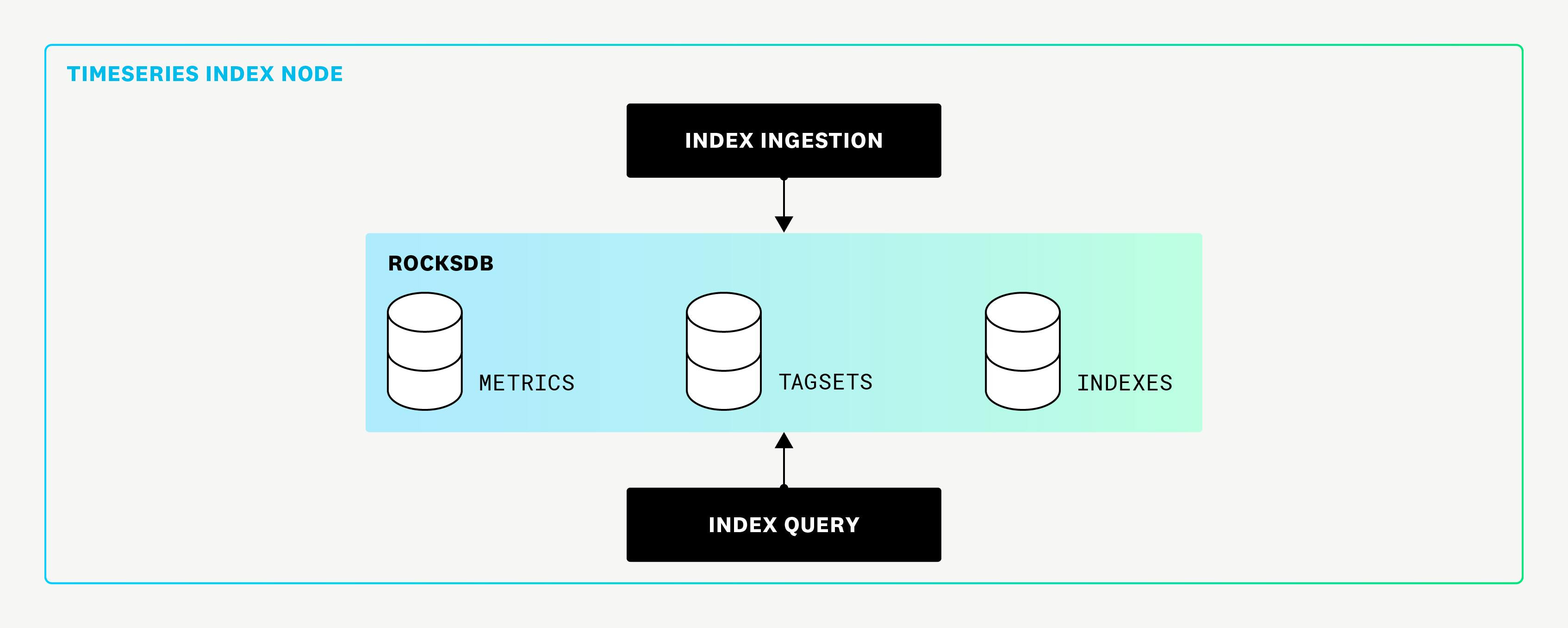
Next-Gen Indexing System
To overcome these challenges, Datadog adopted an inverted index inspired by search engine designs. This strategy indexed every tag in a timeseries along with the associated timeseries identifiers. Key changes included:
Full Tag Indexing: Eliminated reliance on query logs by indexing all tags, ensuring consistent query performance.
Simplified Architecture: Removed SQLite and streamlined the ingestion process, reducing CPU overhead.
Scalability: The new system efficiently handles high-cardinality datasets by reducing the need for full scans.
The inverted index maps well to timeseries queries. For example, querying cpu.total{service:web AND host:i-187} requires just two key-value lookups to retrieve and intersect the results. This is a significant improvement over the original design, where performance depended on whether an index already existed.
Intranode Sharding
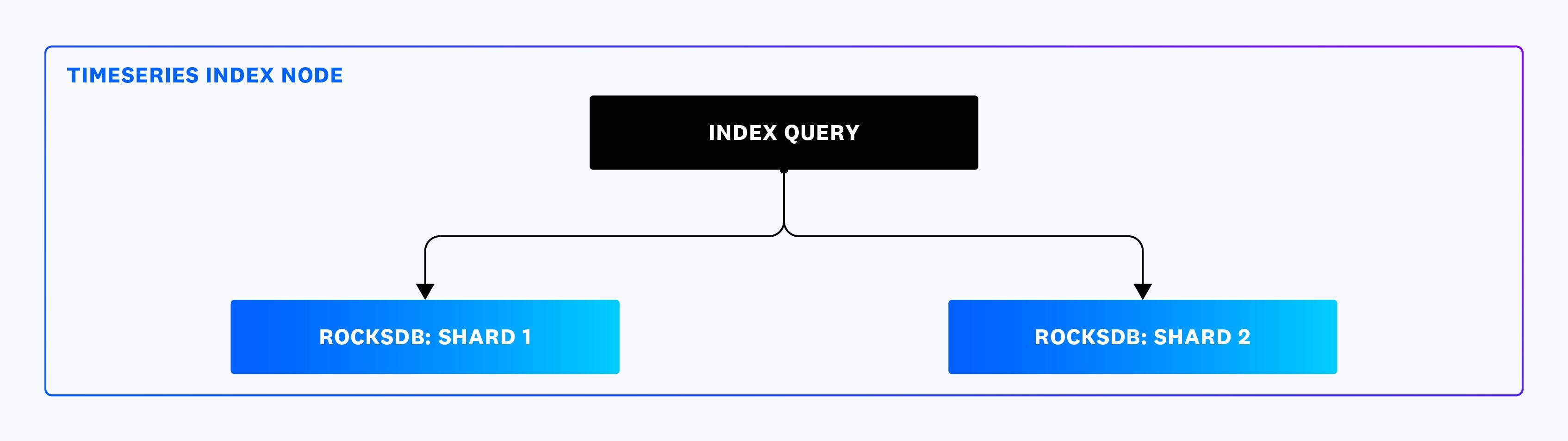
One major limitation of the original system was its inability to scale query execution across multiple CPU cores on a single node. To address this, the new system introduced intranode sharding, splitting RocksDB instances into multiple shards. Data is distributed across shards using hashed timeseries IDs.
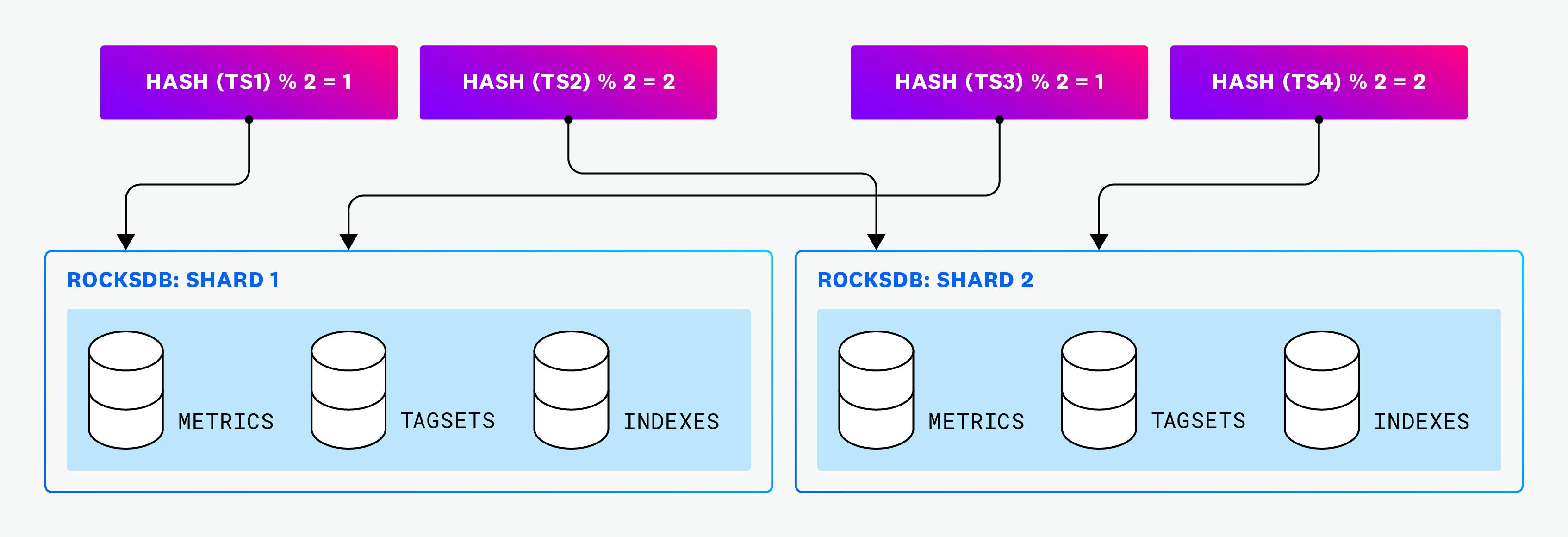
Sharding enabled:
Parallel Query Execution: Queries are executed simultaneously across shards, significantly improving performance.
Better Resource Utilization: Larger cloud nodes with more CPU cores could be effectively used, reducing the number of nodes required.
Transition to Rust
While the original implementation in Go was effective, it faced limitations with resource-intensive tasks. Nearly 30% of CPU resources were spent on garbage collection. Transitioning to Rust improved:
Performance: Rust’s compiled nature and memory management allowed CPU-intensive operations, such as merging timeseries IDs, to execute up to 3x faster than in Go.
Scalability: Rust’s efficiency reduced the time required for optimizations, making the system more robust.
Results
The new indexing system brought transformative changes:
Improved Query Performance: Query timeouts reduced by 99%, with 20x higher cardinality metrics supported on the same hardware.
Cost Efficiency: Operational costs decreased by nearly 50% due to better resource usage.
Scalability and Reliability: Consistent query performance was ensured by always indexing all tags.
Lessons Learned
Adopt Proven Techniques: Drawing inspiration from established practices like inverted indexing enabled robust solutions to complex problems.
Invest in Scalability: Building systems that scale horizontally ensures long-term efficiency as data grows.
Parallelization is Key: Enabling parallel query execution across multiple shards improves performance and fully utilizes modern hardware capabilities.
Choose the Right Technology: Transitioning from Go to Rust for resource-intensive tasks demonstrated the importance of selecting the right language for performance-critical systems.
Optimize for Real-Time Performance: Designing for low latency is critical in environments that rely on up-to-date metrics.
The Full Scoop
To learn more about this, check Datadog's Blog post on this topic