

How Uber Scaled Incentive Optimisation by 40x
Learn more about the hybrid Ray-Spark architecture that transformed Uber’s budget allocation system


TL;DR
Situation
Uber's rides business relies heavily on numerous machine learning models and optimization algorithms to manage its large and complex marketplace. Achieving computational efficiency at this scale is challenging, especially when many system components can be processed in parallel.
Task
Uber needed to enhance the performance of its mobility marketplace allocation tuning system. The goal was to improve computational efficiency, increase developer productivity, and reduce code complexity, thereby enabling more effective tuning of the marketplace levers such as driver incentives and rider promotions.
Action
Uber adopted Ray, a distributed computing platform, to streamline and scale its machine learning workflows. Key actions included:
Framework Integration: Transitioned from traditional computing systems to Ray for handling distributed machine learning tasks.
Dynamic Pricing Optimization: Leveraged Ray to run complex pricing algorithms in real-time, ensuring that prices adjust dynamically based on demand and supply.
Demand Prediction: Used Ray to scale predictive models, allowing for accurate forecasting of ride demand across various regions.
Resource Efficiency: Enabled efficient resource allocation through parallelized model training and deployment, reducing latency in decision-making processes.
Result
The integration of Ray led to performance improvements of up to 40 times in Uber's mobility marketplace allocation tuning system. This enhancement unlocked new capabilities, increased iteration speed, reduced incident mitigation time, and lowered code complexity, thereby improving overall developer productivity.
Use Cases
Mobility Marketplace Allocation, Computational Efficiency, Optimisation Algorithms
Tech Stack/Framework
Apache Spark, Apache HDFS, Ray, Amazon S3, Pandas, XGBoost, Horovod
Explained Further
Motivation and Background
Uber’s mobility marketplace relies on weekly adjustments to control variables like ride discounts and driver incentives, requiring the processing of large datasets and optimizing models across cities with strict timelines. While Apache Spark excelled in data processing and feature engineering, it struggled with lightweight Python operations and Pandas workflows, creating bottlenecks in scalability. Attempts to address these limitations with UDFs and multi-threading proved insufficient, prompting Uber to adopt Ray, a distributed compute framework optimized for parallel Python operations.
Architecture Solutions
Uber designed a hybrid architecture that combined the strengths of Spark and Ray. This approach addressed the computational inefficiencies in their existing system while preserving the benefits of Spark’s robust data processing capabilities.
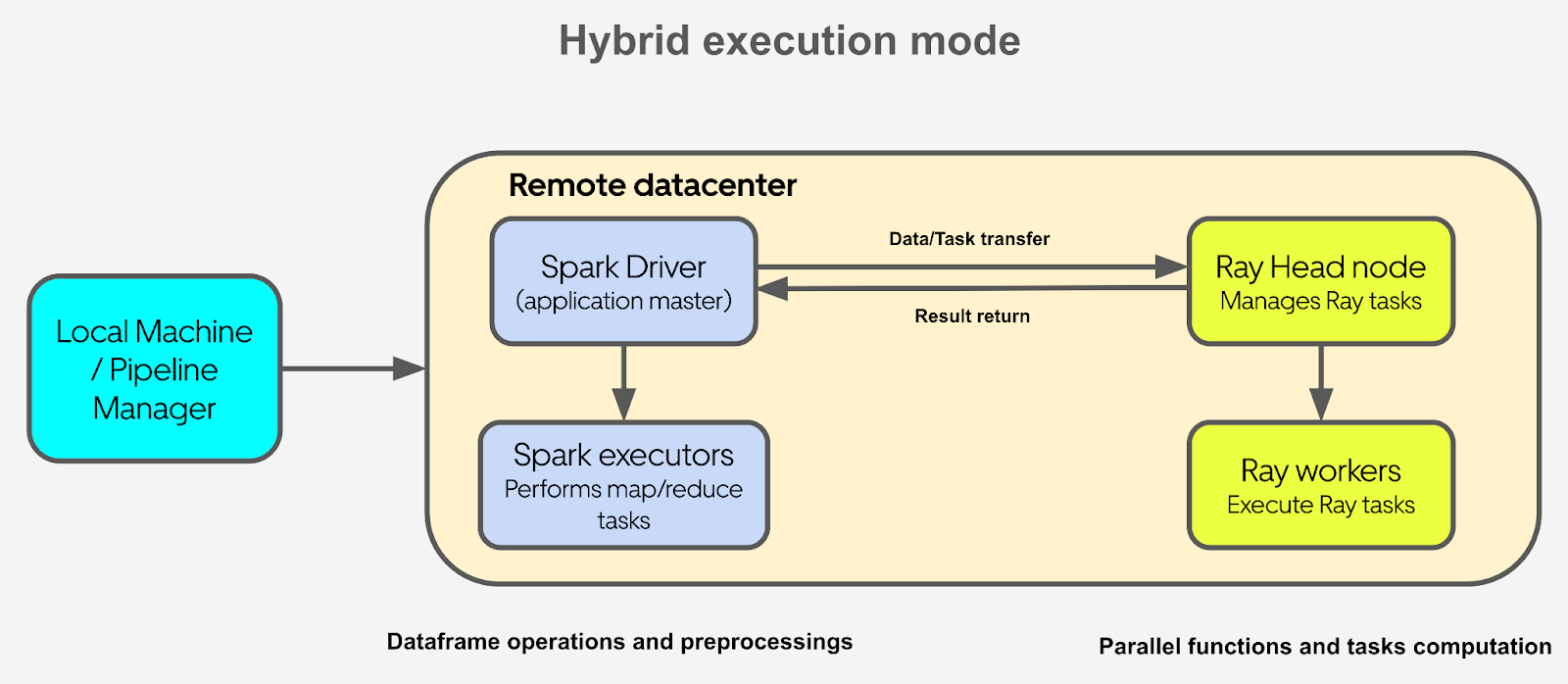
Role of Spark:
Spark remained the backbone for feature engineering and structured data processing tasks, which involve transforming raw data into meaningful inputs for optimization models.Introduction of Ray:
Ray was integrated to parallelize lightweight Python computations that Spark struggled to handle. For example, running optimization functions for thousands of cities—each completing in 1-2 seconds—was offloaded to Ray. This allowed these tasks to be executed concurrently, significantly improving performance.Seamless Transition:
By splitting workflows between Spark and Ray, Uber avoided the need for a costly and disruptive full migration. This hybrid architecture leveraged Spark’s batch processing and Ray’s parallelism for a more efficient system.
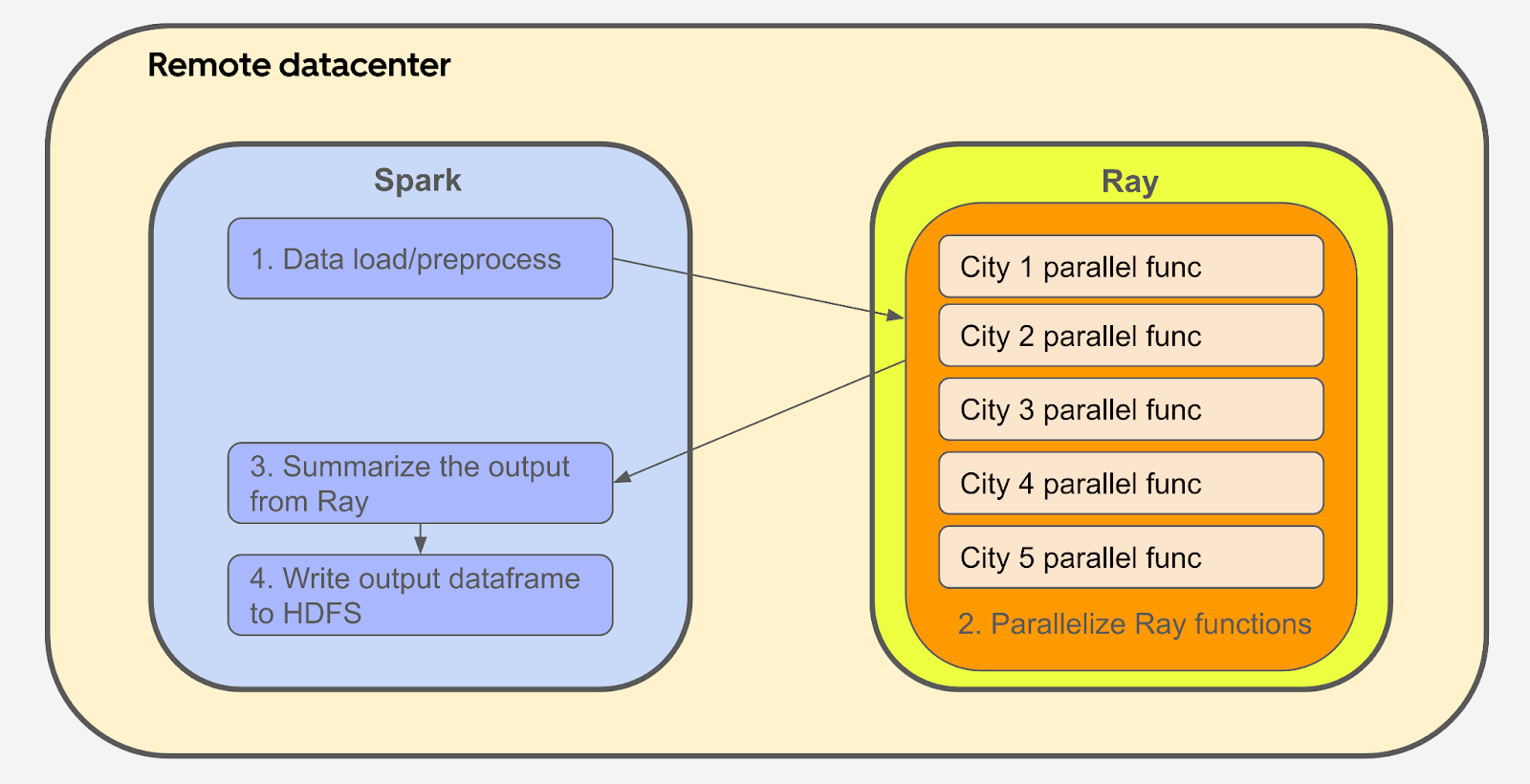
This architecture not only improved computational performance but also reduced code complexity, enabling faster development and debugging cycles.
Use Cases at Uber: ADMM Optimizer
Uber uses the Alternating Direction Method of Multipliers (ADMM) as a core component in its incentive budget allocation system. ADMM is particularly suited for solving Uber's optimization problem because of its ability to handle non-linear, non-convex, and differentiable constraints effectively while maintaining scalability through parallelization.
The ADMM optimizer divides a total incentive budget into allocations for various city-levers, imposing constraints like smoothness conditions from machine learning models. Using Ray, Uber parallelizes the computationally lightweight optimization tasks for individual cities, where each task takes only 1-2 seconds. However, the sheer volume of these concurrent computations necessitated a solution to eliminate bottlenecks.
The ADMM optimization workflow, as implemented at Uber, involves the following steps:
Initialize the Problem: Define the constraints, variables, and objectives.
Iterative Optimization Loop:
Solve individual city problems in parallel using Ray.
Summarize city-level results using Spark.
Update cross-city constraints and slack variables with Spark.
Check convergence criteria with Spark.
Record Results: Store the optimal allocations, metadata, and convergence variables.
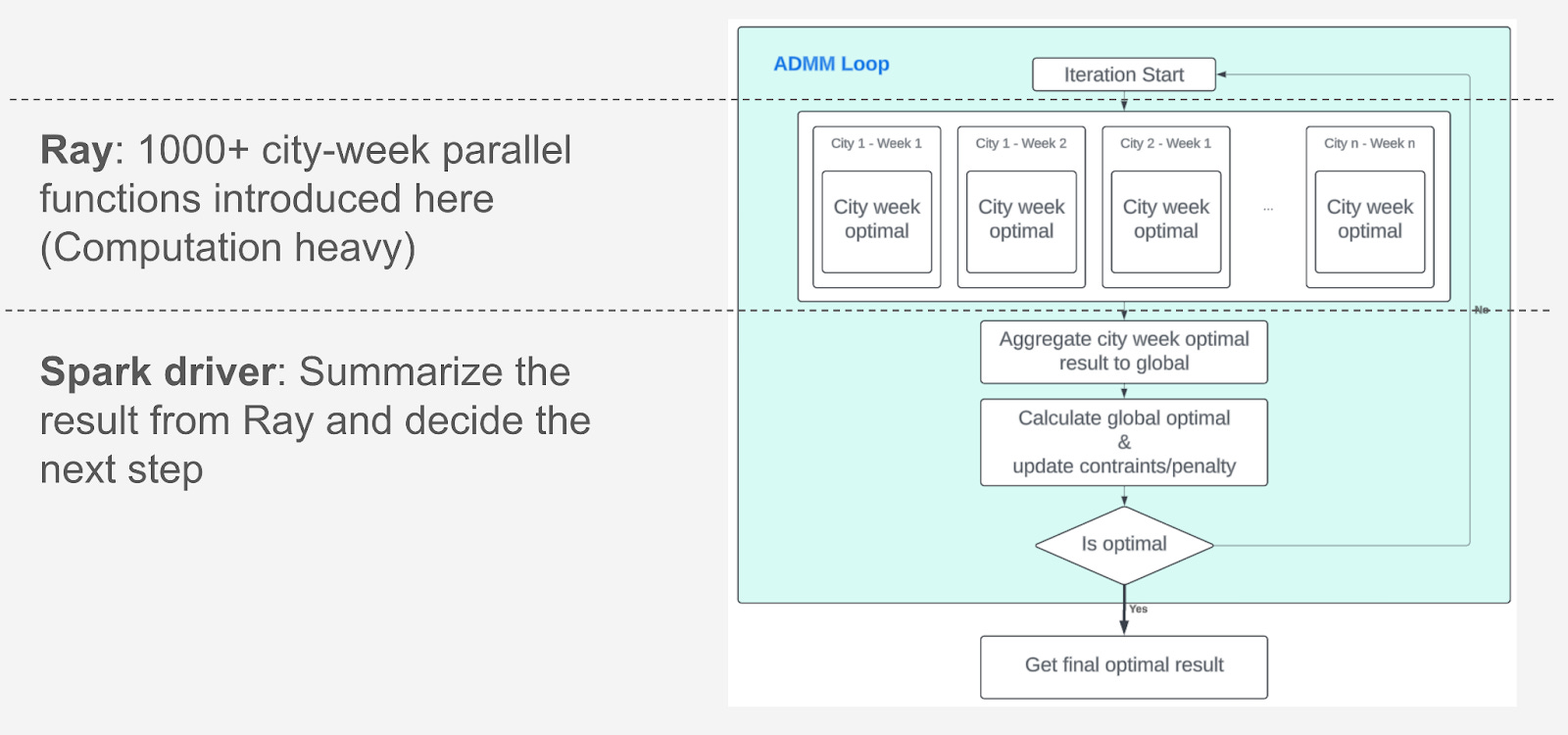
The integration of Ray for parallel computations resulted in a 40x performance improvement in budget allocation. This approach enables Uber to scale the optimizer seamlessly as cities or variables are added, ensuring efficient and timely budget allocations across its global operations.
KubeRay Back End Support from Uber Michelangelo
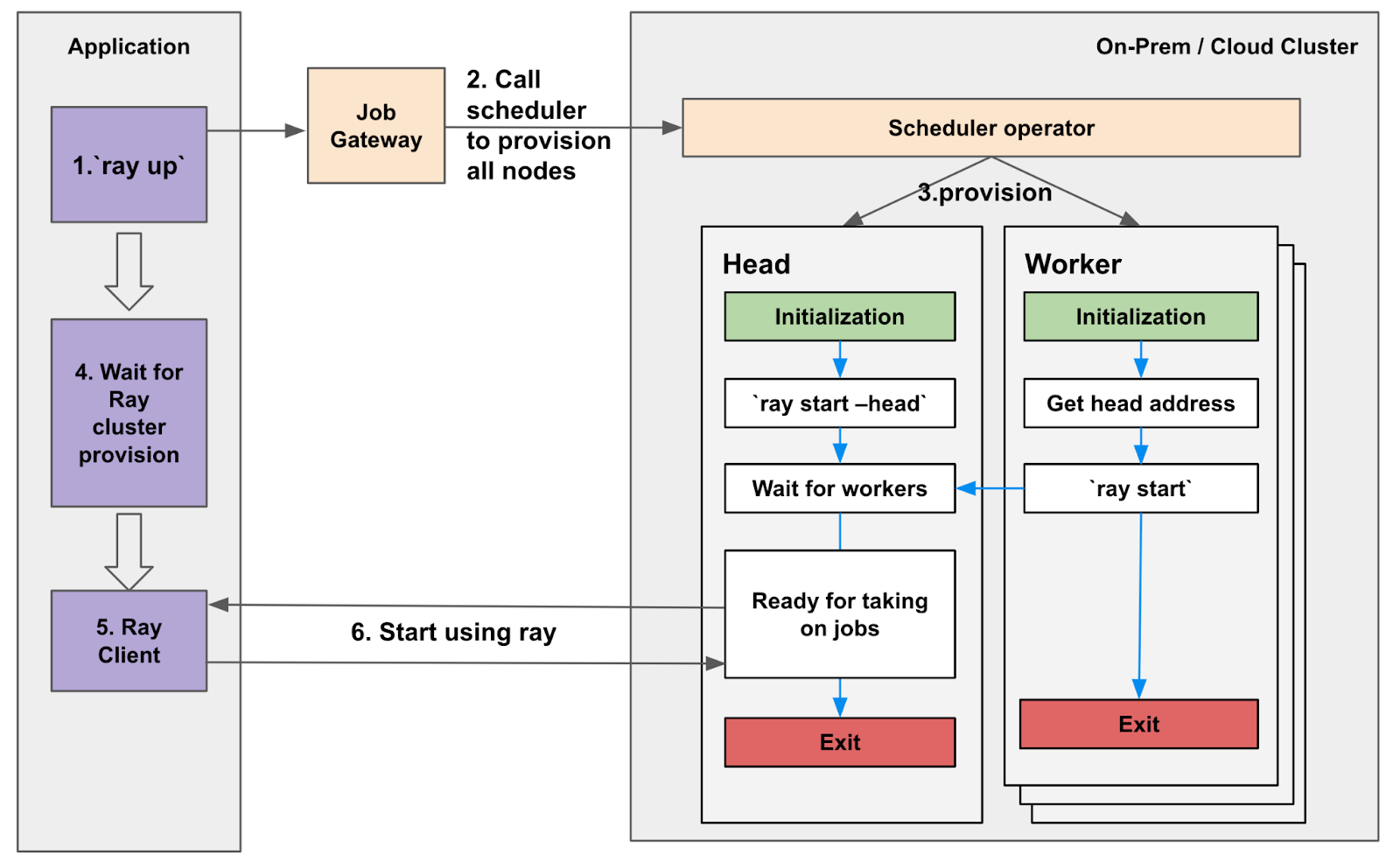
To support the scalability and efficiency of Ray-based applications, Uber’s Michelangelo AI platform team built a robust Ray back end. This system dynamically provisions Ray clusters based on job-specific requirements like nodes, CPU, GPU, and memory. The back-end workflow includes:
Dynamic Cluster Provisioning:
Ray clusters are initialized when a job is submitted.
The head node is established and connects to worker nodes to coordinate distributed execution.
Resource allocation and release are automated to optimize platform efficiency.
Integration with Open-Source Tools:
Michelangelo extends Ray's core capabilities by integrating with popular frameworks like:Horovod for distributed deep learning.
Ray XGBoost and Ray Data for model training.
Ray Tune for fine-tuning machine learning models.
Kubernetes-Based Job Controller:
In 2023, Uber migrated its resource management system to a Kubernetes-based Michelangelo Job Controller, enhancing the scalability and efficiency of both on-premises and cloud resources. Key benefits include:Automated Resource Allocation: Jobs are dynamically assigned to resource pools based on organizational and workload requirements, reducing manual intervention.
Dynamic Scheduling: A federated scheduler intelligently matches jobs to available clusters, preventing oversubscription and scheduling failures.
Cluster Health Monitoring: Continuous monitoring ensures jobs are allocated only to healthy clusters.
Simplified User Experience: The system abstracts infrastructure complexities, allowing users to focus on workloads without worrying about resource management.
Future-Proof Design:
The architecture supports emerging technologies, cloud bursting, and new hardware, enabling scalability and extensibility.
By early 2024, Uber migrated all XGBoost and deep learning training jobs to this new system, which also supports use cases like fine-tuning large language models (LLMs) and optimization tasks. This modernized back end ensures Uber’s AI workloads are efficiently managed and future-ready.
Results
The hybrid architecture and use of ADMM delivered transformative results for Uber’s marketplace allocation tuning system:
40x Performance Improvement: Computational efficiency improved dramatically, enabling faster processing of complex optimization problems.
Enhanced Scalability: The system now accommodates a growing number of cities and decision variables without performance degradation.
Improved Decision-Making: Faster optimization cycles allow Uber to adjust marketplace levers dynamically, improving rider and driver experiences.
Streamlined Development: Developers benefit from a simplified codebase, enabling faster debugging and iteration cycles.
Lessons Learned
Leverage the Right Tools: Combining frameworks like Ray and Spark allows for efficient handling of diverse computational tasks.
Simplify for Scalability: Flexible and hybrid architectures reduce long-term technical debt and support growth.
Embrace Parallelism: Distributed frameworks like Ray unlock performance gains for complex workflows.
The Full Scoop
For a deeper dive into Uber’s implementation of Ray and ADMM, visit the original article on Uber engineering blog