

Improving Search for 1B+ LinkedIn Users with GenAI
Discover how LinkedIn used AI to refine search suggestions and create a better user experience


TL;DR
Situation
LinkedIn’s search bar helps over 1 billion users find jobs, profiles, and companies. The accuracy of instant search suggestions is key to a smooth experience. Manual evaluations were too slow, so LinkedIn automated the process using GenAI with OpenAI’s GPT via Azure.
Task
The goal was to create an AI-powered system to evaluate search suggestion quality. It needed to be scalable, accurate, and adaptable to different search types. A scoring system was required to track improvements and reduce reliance on manual reviews.
Action
Defined quality guidelines to classify suggestions as high-quality (1) or low-quality (0).
Built a golden test set with 200 queries per category to cover diverse search intents.
Engineered GPT-based prompts tailored for different search result types.
Established an automated scoring system to evaluate search accuracy at various levels.
Implemented an evaluation pipeline to process and score search suggestions in real-time.
Conducted an experiment expanding plain-text search suggestions using high-quality LinkedIn posts.
Result
The AI-driven system improved search quality and reduced evaluation time. The quality score for search suggestions increased by 6.8%, cutting poor recommendations by 20%. Evaluations that took days now finish in hours, enabling faster improvements.
Use Cases
Search Optimization, Query Completion, Automated Search Evaluation
Tech Stack/Framework
OpenAI GPT, Prompt Engineering
Explained Further
Automated GenAI-Driven Search Quality Evaluation
LinkedIn’s search bar is a crucial tool for over 1 billion members, helping them find jobs, profiles, companies, and more. The quality of search suggestions plays a vital role in shaping user experience, making it essential to maintain accuracy and relevance. Historically, manual evaluation was used to assess search quality, but this approach became impractical due to LinkedIn’s growing scale.
To address this, LinkedIn introduced the GenAI Typeahead Quality Evaluator, leveraging OpenAI’s GPT model via Azure to automate search quality evaluation. This system enables faster assessments, improves the accuracy of search suggestions, and reduces reliance on manual reviews.
Establishing Clear Criteria for Search Quality
Before implementing AI-driven evaluations, LinkedIn established clear measurement guidelines to ensure consistency and accuracy. These guidelines act as a foundation for prompt engineering and help define how AI evaluates search suggestions.
Two major challenges had to be addressed:
Diverse Search Intents: Users search for different types of results, including people, jobs, companies, and skills, requiring tailored evaluation criteria.
Personalization: Search suggestions are personalized, meaning the same query can yield different results for different users.
To overcome these issues, LinkedIn categorized search suggestions as high-quality (1) or low-quality (0) to minimize subjectivity. Evaluations were designed to occur after the user finishes typing, ensuring sufficient context for accurate assessments.
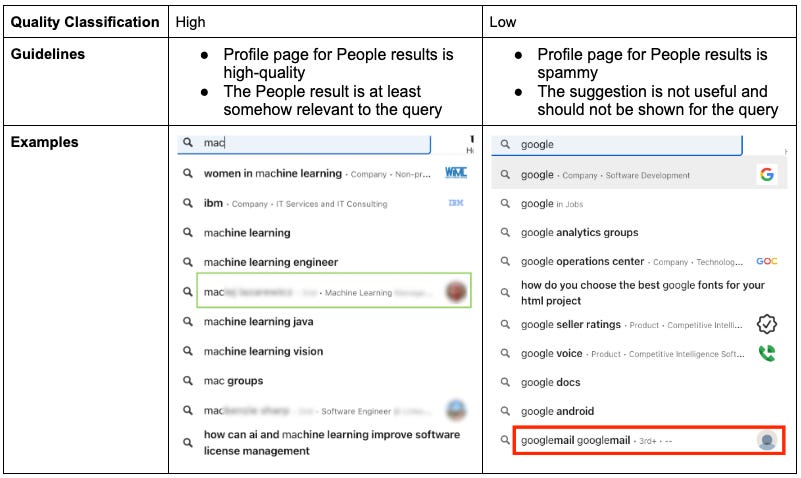
Building a Test Dataset to Benchmark Quality
A golden test set was created to benchmark LinkedIn’s search quality. This test set consists of query-member ID pairs, sampled from real platform traffic, ensuring it represents different user experiences.
Key components of the test set:
Comprehensive Intent Coverage: 200 queries per category (People, Companies, Jobs, Skills, etc.) were selected based on click signals to determine user intent.
Bypass & Abandoned Sessions: 200 queries were sampled from cases where users either bypassed search suggestions or abandoned LinkedIn after searching.
User Frequency Consideration: Member Life Cycle (MLC) data was used to sample frequent users (weekly/daily active members), ensuring data reflected real-world usage.
Designing AI Prompts for Better Evaluation
With a structured test set in place, LinkedIn leveraged prompt engineering to instruct OpenAI’s GPT model on evaluating search quality.
Each prompt template follows a standardized format:
Identity: The AI acts as a search evaluator.
Task Guidelines: Defines how AI should assess a search suggestion.
Examples (Few-shot learning): Provides AI with reference cases to improve evaluation accuracy.
Input: The user’s search query and corresponding suggestions.
Output: AI-generated reasoning and a quality score (1 or 0).
For example, a People search prompt includes structured examples like:
Query: "David W."
Suggestion: "David W. - Engineering Lead at XX"
Reasoning: Likely a relevant first-degree connection.
Score: 1 (High Quality)
The output reasoning follows a chain-of-thought approach, proven to improve GPT evaluation performance.
Evaluating the Search Quality Score
Since top-ranked search suggestions are more visible and impact user experience the most, LinkedIn developed four key quality metrics:
Quality Score of Top Suggestion (TyahQuality1)
Average Quality Score of Top 3 Suggestions (TyahQuality3)
Average Quality Score of Top 5 Suggestions (TyahQuality5)
Average Quality Score of Top 10 Suggestions (TyahQuality10)
AI assigns 1 (high-quality) or 0 (low-quality) scores to each suggestion in a session, and the final search quality score is calculated by averaging these values across all sessions.
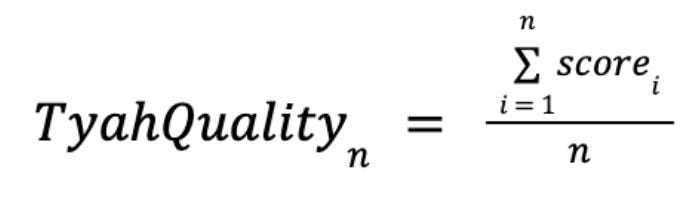
Automating the Search Evaluation Process
The GenAI search quality evaluation pipeline follows a structured five-step process:
Generate test queries using experiment configurations.
Collect search results from the LinkedIn backend.
Generate GPT prompts tailored for different search result types.
Batch-call GPT API to evaluate search suggestions.
Process results and calculate TyahQuality scores.
This pipeline allows LinkedIn to quickly assess search experiments and monitor search quality at scale.

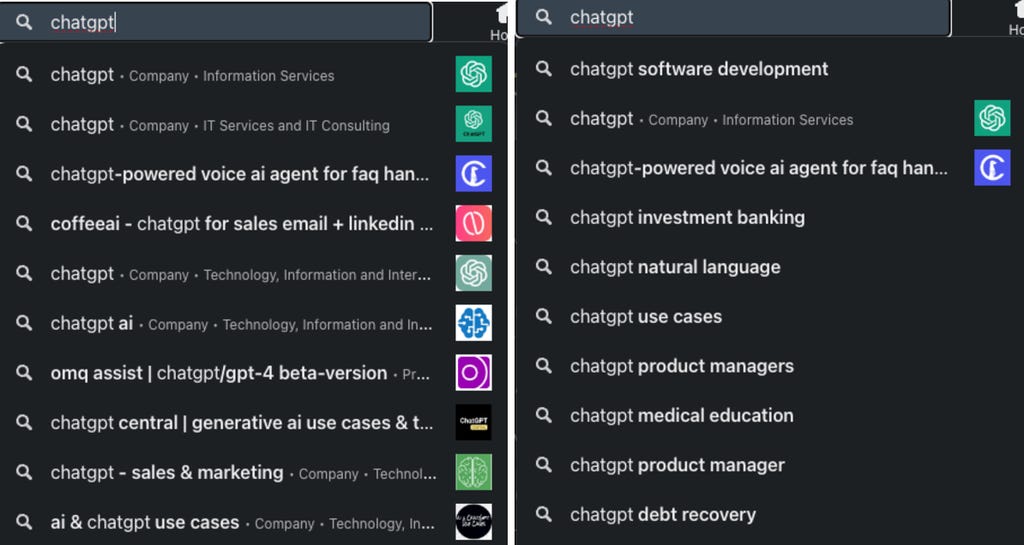
Real-World Experiment: Improving Search Suggestions
To showcase how the system works, LinkedIn ran an experiment to expand plain-text search suggestions by incorporating high-quality LinkedIn post content.
Before the change, search suggestions were limited to predefined entities (people, jobs, companies). After the change, short phrases from high-quality LinkedIn posts were added to the suggestion pool, improving content discovery.
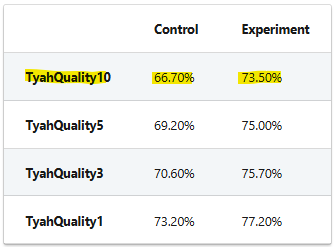
This experiment resulted in a 6.8% improvement in typehead quality score (TyahQuality10)
Lessons Learned
The GenAI-powered search quality evaluator proved effective in scaling search quality assessments while improving evaluation speed and accuracy.
Defining evaluation criteria was challenging due to the complexity of search results. Eliminating ambiguity was crucial.
Prompt engineering required multiple iterations to align AI evaluations with human assessments.
The automated system significantly reduced evaluation time, cutting down a process that once took days or weeks to just a few hours.
The Full Scoop
To learn more about the implementation, check LinkedIn Blog post on this topic