

ML Training Too Slow? Yelp’s 1,400x Speed Boost Fixes That
Discover the data pipeline and GPU optimisations that made it happen


TL;DR
Situation
Yelp's ad revenue relies on predicting which ads users are likely to click on, using a model called "Wide and Deep Neural Network." Initially, training this model on 450 million data samples took 75 hours per cycle, which was too slow. Yelp wanted to handle 2 billion samples and reduce training time to under an hour per cycle.
Task
The goal was to speed up the training process by improving how data is stored and read, and by using multiple GPUs to handle more data at once.
Action
Data Storage: Yelp stored the training data in Parquet format on Amazon's S3 storage, which works well with their data processing system, Spark. They found that a tool called Petastorm was too slow for their needs, so they developed their own system called ArrowStreamServer. This new system reads and sends data more efficiently, reducing the time to process 9 million samples from over 13 minutes to about 19 seconds.
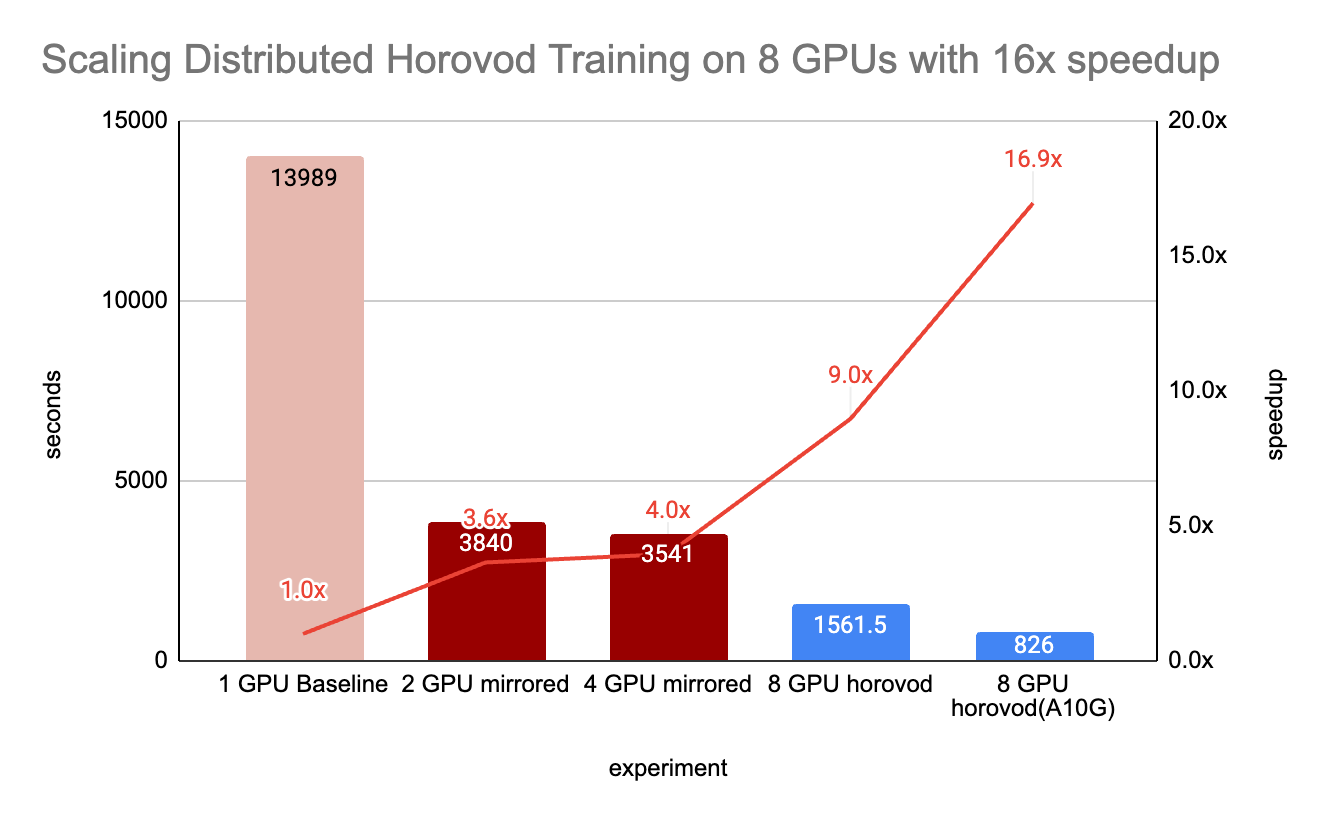
Distributed Training: Yelp initially used a method called MirroredStrategy to train the model on multiple GPUs but found it didn't work well as they added more GPUs. They switched to a tool called Horovod, which allowed them to efficiently use up to 8 GPUs at once, significantly speeding up the training process.
Result
By implementing these changes, Yelp achieved a total speed increase of about 1,400 times in their model training. This means they can now train their ad prediction models much faster, allowing them to handle more data and improve their ad services.
Use Cases
Large-Scale ML Training, ML Training Optimisation, Enhancing Data Pipeline Efficiency
Tech Stack/Framework
TensorFlow, Horovod, Keras, PyArrow, Amazon S3, Apache Spark
Explained Further
The Challenge
At Yelp, the Wide and Deep Neural Network model plays a crucial role in predicting ad click-through rates, directly impacting revenue. However, training this model on large-scale tabular datasets was becoming increasingly time-consuming. Initially, processing 450 million samples per training cycle required 75 hours, which was not sustainable as the data volume expanded to 2 billion samples.
The main challenges included:
Data Storage Efficiency
Yelp primarily stores datasets in Parquet format on Amazon S3, ensuring compatibility with its Spark-based ecosystem.
Existing solutions like Petastorm proved inefficient, especially due to tabular data’s structure, leading to the need for a more optimised approach.
Distributed Training
TensorFlow’s MirroredStrategy provided good initial scalability, but performance suffered beyond 4 GPUs, creating bottlenecks in CPU, I/O, and GPU utilization.
Yelp needed a better distributed training strategy to maximize speed improvements as they scaled their infrastructure.
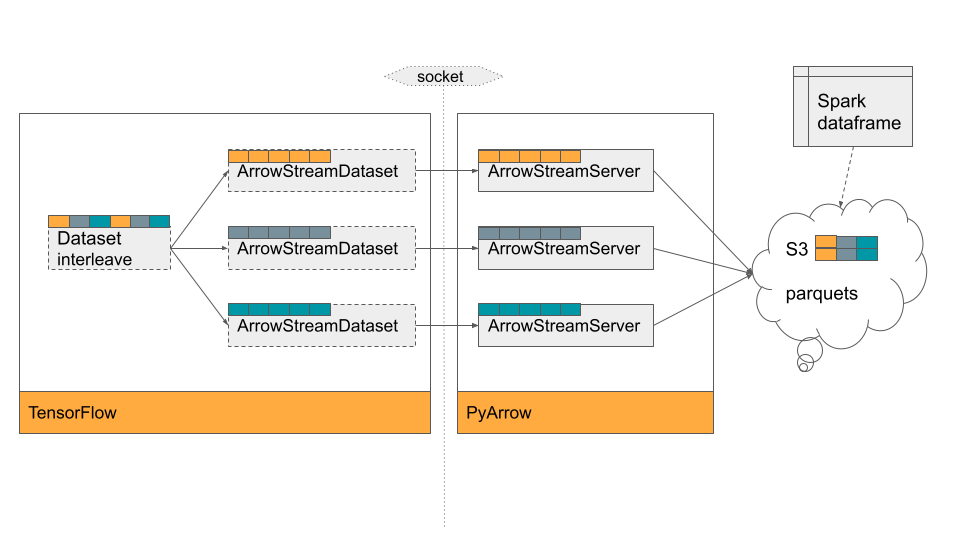
Data Storage Optimisation with ArrowStreamServer
Yelp initially relied on Petastorm to load training data from S3, but it struggled with large tabular datasets. The inefficiency stemmed from re-batching operations, which caused tensor explosions due to millions of small tensors being created.
To address this, Yelp explored ArrowStreamDataset from TensorFlow I/O, which offered a faster alternative. However, it only supported local Feather storage, which was incompatible with their ecosystem. This led to the development of ArrowStreamServer, a custom-built solution using PyArrow.
How ArrowStreamServer Works:
Reads & Batches Data Efficiently: Fetches and batches training data directly from S3.
Serves as a Data Streamer: Delivers RecordBatch streams over a network socket for consumption.
Enables Parallel Processing: Runs as a separate process, avoiding Python’s Global Interpreter Lock (GIL).
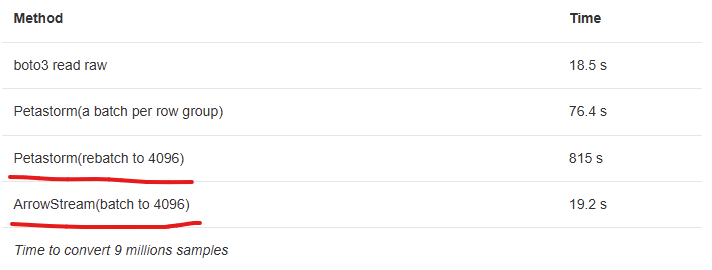
Performance Comparison:
By implementing ArrowStreamServer, Yelp drastically reduced data loading times from over 13 minutes to just 19 seconds.
Scaling Training with Horovod
As Yelp's training data expanded from hundreds of millions to billions of samples, scaling efficiently across multiple GPUs became essential to meet training time goals. Initially, TensorFlow’s MirroredStrategy was used for multi-GPU training. This approach provided near-linear scaling up to 4 GPUs, significantly reducing training time.
However, when scaling beyond 4 GPUs to 8 GPUs, performance gains plateaued due to several bottlenecks:
Low GPU, CPU, and I/O utilization indicated inefficient workload distribution.
Dataset sharding issues in TensorFlow’s Keras data handler prevented effective parallelization.
Synchronization overhead reduced the benefits of additional GPUs.
To overcome these limitations, Yelp transitioned to Horovod, a more scalable distributed training framework.
Why Horovod?
In Yelp’s benchmarking tests, Horovod achieved linear scaling up to 8 GPUs, delivering a significant speed improvement compared to MirroredStrategy. The key advantages of Horovod include:
Efficient Process Management
Horovod uses one process per GPU, optimising resource allocation and preventing inefficiencies caused by Python’s Global Interpreter Lock (GIL).
Optimised Gradient Synchronization
By converting sparse gradients into dense gradients, Horovod significantly improves memory efficiency and accelerates all-reduce operations.
For large batch sizes and models with numerous categorical features, dense gradients improve overall training speed.
Challenges in Implementing Horovod
While switching to Horovod improved performance, integrating it with Yelp’s Keras-based WideDeepModel introduced additional complexities:
Modifying Keras’s Gradient Computation
Horovod’s
DistributedOptimizernormally overrides the_compute_gradientsmethod to integrate with Keras optimizers.However, Keras’s premade WideDeepModel calls
GradientTapedirectly, bypassingminimize.To resolve this, Yelp overrode the
train_stepmethod in WideDeepModel, ensuring compatibility with Horovod.
Managing Threading and Memory Overload
When running on multiple GPUs, thousands of threads were spawned, leading to threading storms and out-of-memory (OOM) crashes.
To prevent oversubscription of CPU and memory, Yelp optimised thread pool settings for each GPU:
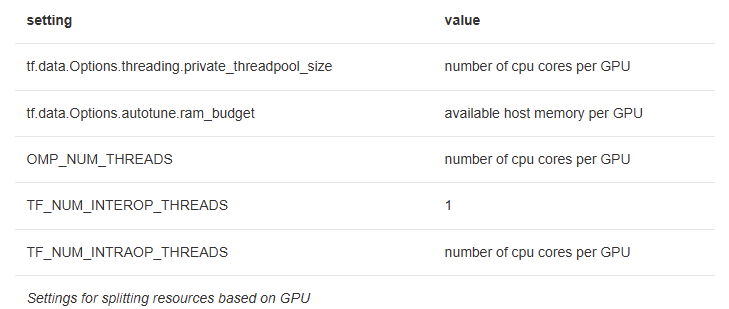
These optimisations ensured stable resource allocation per GPU, allowing Yelp to scale training smoothly while avoiding excessive thread contention and memory issues.
Bringing Everything Together: Spark ML Integration
To seamlessly integrate these optimisations into Yelp’s Spark ML pipeline, they developed KerasEstimator, which:
Stores transformed features in S3 and serves them via ArrowStreamServer.
Uses ArrowStreamDataset to efficiently stream training data.
Implements HorovodRunner and TFMirrorRunner to train Keras models directly within Spark executors.
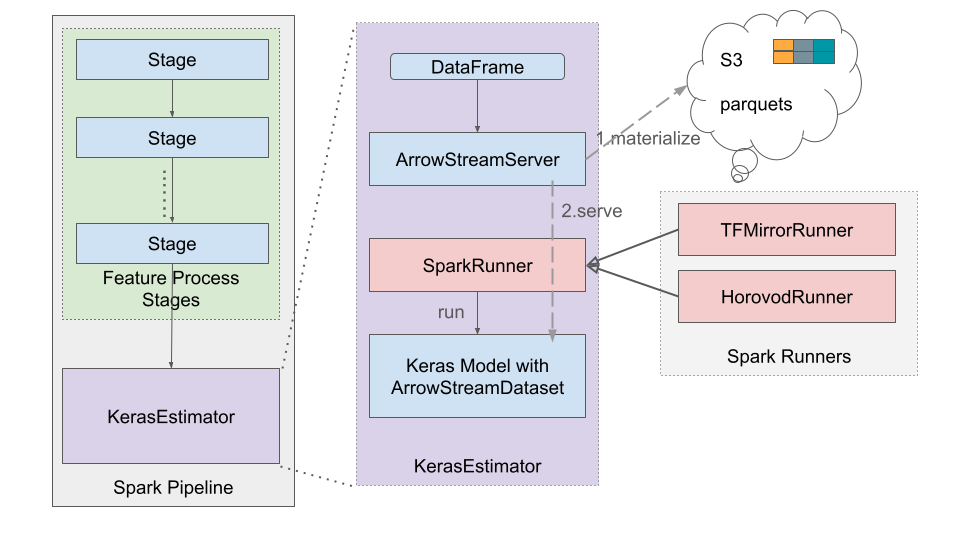
This setup enables efficient, large-scale neural network training while maintaining compatibility with existing Spark infrastructure.
Results
Benchmarking on 2 billion samples showed significant improvements. ArrowStream optimisation reduced training time 85.8x, cutting it from 75 hours for 450 Millions Samples.
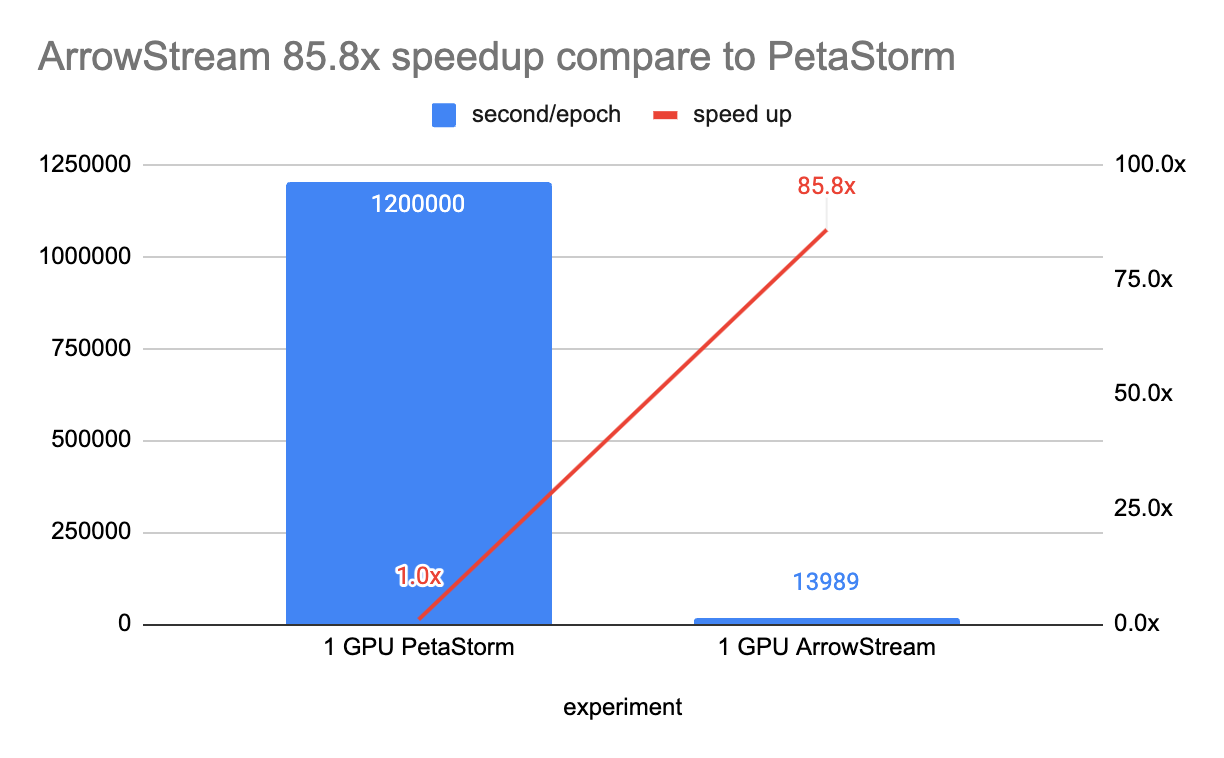
Distributed training with Horovod added a 16.9x boost, achieving a total 1,400x speedup.
Lessons Learned
Optimising I/O is critical for training efficiency: Slow data loading can significantly impact training performance. Switching from Petastorm to ArrowStreamServer drastically improved speed.
Scalability requires choosing the right distributed training method: TensorFlow’s MirroredStrategy worked up to 4 GPUs but became inefficient beyond that. Switching to Horovod allowed near-linear scaling up to 8 GPUs.
Thread and memory management is essential for multi-GPU training: Excessive threads led to out-of-memory (OOM) issues, requiring careful tuning of CPU and memory allocations per GPU.
The Full Scoop
To learn more about this, check Yelp's Engineering Blog post on this topic