

Scaling Real-Time Analytics: How Expedia Cut Costs by 40% While Supporting 450+ Concurrent Users
Learn how the Optics Framework enabled seamless data insights with <15-second latency for global teams


TL;DR
Situation
Expedia Group needed a scalable and cost-effective real-time analytics solution (<15 seconds latency) to process high-volume data (~4500 events/sec) and support global service partners in optimizing operations and enhancing performance.
Task
Design a solution to process and present real-time data with blazing-fast query speeds while addressing limitations of existing tools (e.g., Snowflake and Looker) in terms of scalability, latency, and user experience.
Action
Developed a new architecture using Apache Druid for real-time ingestion, optimized microservices for data processing, and built a custom modular UI library with a Data Resolver API to deliver tailored analytics based on user roles.
Result
The solution achieved a 5x increase in user base, 30-40% reduction in costs, 15-second data latency, and 99.9% SLA uptime. It supported 1,800 users with sub-1-second response times, enhancing decision-making and operational efficiency globally.
Use Cases
Real-Time Insights, Operational Efficiency, Scalability for Concurrent Users
Tech Stack/Framework
Python, Apache Druid, Apache Hive, Apache Kafka, Looker, Snowflake
Explained Further
Real-Time Challenges for Expedia
Handling real-time data at scale presents unique challenges. Traditional analytics workflows using raw data ingestion into warehouses like Snowflake followed by visualization tools like Looker—struggle to maintain low latency for high-volume, event-driven systems. Processing 4,500 unique events/sec (~4.5 MB/sec) while ensuring data freshness and responsiveness demanded a radical rethinking of the architecture.
Iterative Evolution of the Solution
The Optics framework was developed iteratively, with each phase addressing the limitations of the previous system.
1st Iteration: Python Microservices + Snowflake + Looker
In the initial phase, the architecture was built on widely available tools to provide a real-time analytics solution. This system used Kafka for ingesting event streams, Python-based microservices to preprocess the data, Snowflake for data storage, and Looker for reporting and visualization.

Strengths:
Quick Deployment: Leveraged existing tools to quickly develop a working analytics pipeline.
Basic Functionality: Met basic real-time requirements for a lighter workload.
Challenges:
Scalability Issues: As the volume of events increased to ~4,500 events/sec (4.5 MB/sec), Snowflake struggled to keep up with the continuous data ingestion. Query performance degraded significantly due to delays in indexing new data.
Latency Problems: Under peak conditions, reports for ~100 concurrent users took more than 2 minutes to load, far exceeding real-time expectations.
High Costs: Continuous real-time ingestion into Snowflake was resource-intensive, leading to unsustainable infrastructure costs.
User Limitations: Looker’s inability to handle high query refresh rates and concurrent connections created a bottleneck, often requiring service restarts to restore functionality.
This iteration showed the need for a system better optimized for continuous ingestion and real-time querying at scale.
2nd Iteration: Apache Druid + Optimized Microservices
To overcome the challenges of the first iteration, the team adopted Apache Druid, a memory-based database designed for real-time analytics. Druid’s architecture, optimized for fast ingestion and querying, provided significant performance gains for handling continuous event streams.
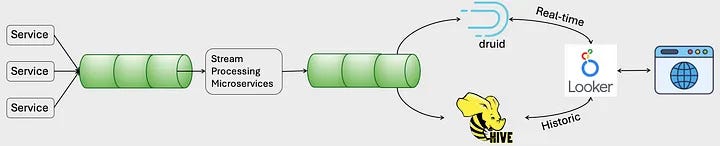
Key Improvements:
Real-Time Ingestion: Druid allowed for direct ingestion from Kafka, enabling near-instant availability of new data for querying. This addressed the latency issues seen in the first iteration.
Optimized Microservices: Python-based microservices were retained but reengineered to handle more advanced preprocessing and analytical workloads before sending data to Druid.
Cost Efficiency: Replacing Snowflake with Druid reduced infrastructure costs by 30%.
Challenges:
Insert-Only Operations: Druid’s append-only ingestion model lacked the ability to handle updates or merges efficiently, requiring careful design of table structures and queries to ensure accuracy in reports.
Analytical Complexity: Druid does not offer the same level of analytic capabilities as Snowflake, pushing more processing responsibilities to the microservices layer. This increased engineering overhead but was necessary to maintain low-latency performance.
Despite these challenges, this iteration provided a scalable and cost-effective solution for real-time analytics, paving the way for further enhancements.
Final Iteration: Optics Framework with Custom Visualization
The limitations of out-of-the-box visualization tools like Looker prompted the team to build a custom Optics Framework, combining a more modular and tailored approach to real-time analytics. This iteration retained the core components from the second iteration while introducing two key innovations:
Data Resolver API:
Introduced to enhance query performance by filtering data at the top of the pipeline.
Utilized Role-Based Access Control (RBAC) to ensure that users could only access data relevant to their profiles.
By reducing the amount of data passed downstream, this API further improved query speeds and reduced resource usage.
Custom Visualization Library:
Built using React, this library provided modular, reusable components for creating visualizations.
The visual components could be easily embedded into existing web applications, making the framework highly pluggable and user-friendly.
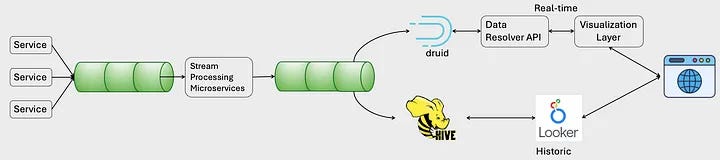
Key Improvements:
Supported over 450 concurrent users, with reports refreshing every 15 seconds.
Delivered sub-second response times, with the 90th percentile response time consistently below 1 second.
Achieved a 100% adoption rate, onboarding more than 1,800 users across multiple teams.
Challenges Overcome:
Concurrent Queries: The Data Resolver API ensured efficient handling of high query volumes by optimizing data filtering at the source.
User Experience: The React-based library provided a seamless and responsive user experience, overcoming the limitations of Looker’s connection handling.
Results
The implementation of the Optics Framework delivered remarkable results:
Performance: Achieved real-time latency of <15 seconds and maintained 99.9% SLA uptime.
User Adoption: Onboarded over 1,800 users with a 100% adoption rate across multiple service teams.
Responsiveness: Report response times consistently stayed under 600ms, with the 90th percentile under 1 second.
Efficiency: Reduced cloud infrastructure costs by 40% compared to the initial system.
Scalability: Successfully supported over 450 concurrent users refreshing reports every 15 seconds, ensuring seamless access to real-time insights.
Lessons Learned
Scalability Requires Trade-offs: Choosing tools like Druid for scalability often means sacrificing some functionality, requiring iterative refinements.
Optimize Early: Filtering data at the source (e.g., with RBAC) minimizes downstream load and improves query performance.
Custom Solutions Over Off-the-Shelf: When tools like Looker fail at scale, custom-built solutions provide better flexibility and efficiency.
Simplification Cuts Costs: Aligning components to specific tasks reduces infrastructure costs while enhancing system performance.
User Experience Drives Adoption: A responsive, intuitive interface ensures actionable insights and boosts user engagement.
The Full Scoop
To learn more about this, check Expedia's Blog post on this topic