


The Art of Substitution: Instacart’s ML Model for Better Shopping Choices
Discover how Instacart uses machine learning to create tailored solutions for unavailable grocery items


TL;DR
Situation
Customers encounter out-of-stock items while shopping on Instacart. Additionally, Instacart faces a key challenge in predicting product availability without real-time inventory data.
Task
Instacart aimed to create a machine learning model that recommends suitable substitutes for unavailable products, closely matching the original items and aligning with customer preferences.
Action
The development involved several key steps:
Cold Start Solutions: For new or infrequently purchased items, the model uses product attributes to find similar replacements.
Ranking Popular Items: Collaborative filtering ranks potential replacements for items with sufficient purchase data.
Retailer Optimization: Tailors recommendations to each retailer's inventory and customer trends.
Availability Check: Ensures that recommended items are in stock, dynamically adjusting suggestions.
Preference Matching: Considers factors like size, flavor, and brand to align with diverse customer needs.
Result
Instacart’s machine learning model has enhanced the replacement process by leveraging both product-specific attributes and customer preferences to recommend substitutes. For popular items with sufficient data, the model ranks replacements using collaborative filtering. For newer or infrequently purchased products, the model suggests replacements based on product features.
Use Cases
Replacement Suggestions, Customer Personalisation, Inventory Optimisation
Tech Stack/Framework
BERT-Based Embeddings, Validation Loss, A/B Testing
Explained Further
Why Do Replacement Decisions Matter?
Instacart faces the challenge of predicting product availability without access to real-time inventory data. To address this, its machine-learning model suggests suitable replacements when items are unavailable during shopping. The model not only provides replacement recommendations to customers but also assists shoppers in selecting the most appropriate substitutes, ensuring a smoother shopping experience and greater customer satisfaction.
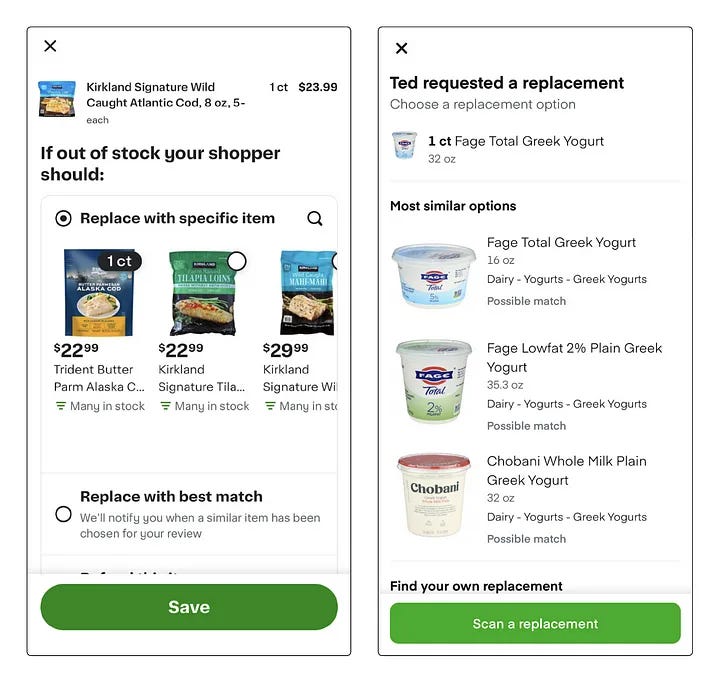
Technical Challenges
Head vs Tail Problem: Popular products have abundant data, making them easier to rank. However, for less frequently purchased (tail) items or newly introduced products (cold start), the model relies on catalog attributes, which may not always result in high customer approval.
Optimizing for Retailer-Specific Inventory: A uniform model across various retailers can introduce biases. Tailoring replacements to each retailer’s unique stock and customer preferences enhances accuracy.
Availability and Ranking Dilemma: Top-ranked replacements may also be out of stock, necessitating the need for lower-ranked items that still align with customer expectations.
Diverse User Preferences: Customer preferences vary across attributes like size, flavor, and brand. Accurately matching these preferences is crucial to avoid dissatisfaction.
Replacement Model Overview
The model suggests substitutes that closely match the original product and align with customer preferences. This user-agnostic subsystem leverages general replacement patterns for Instacart customers.

Part 1: Cold Start Model
Retrieval (Candidate Generation):
For a given product, the system identifies replacement candidates using heuristics:
Engagement: Product pairs from past replacements.
Taxonomy: Products in the same category.
Aisle: Products within the same aisle.
Semantic Proximity: Products similar based on catalog attributes.
To limit candidates, the system employs Levenshtein distance between product names and product popularity. More than 95% of replacements picked by Instacart shoppers are included within this candidate set.
Ranking:
Instacart’s replacement ranking model is a supervised deep-learning system designed to maximize customer approval by prioritizing suitable substitutes for out-of-stock items. The model uses customer impressions for training, employing a pointwise ranking approach for simplicity and seamless integration with business logic.
It refreshes weekly through automated pipelines to maintain coverage and address the cold start problem. Features include product name (text), categorical attributes (e.g., brand, size, aisle), binary attributes (e.g., dietary labels), and pre-trained embeddings from the search team. Training data is derived from positive and negative customer interactions, ensuring robust and relevant recommendations.
Model Architecture and Evaluation:
The model uses a Siamese network to process two input vectors simultaneously, creating comparable outputs. This 'two-tower' architecture is prevalent in recommendation and search ranking applications.
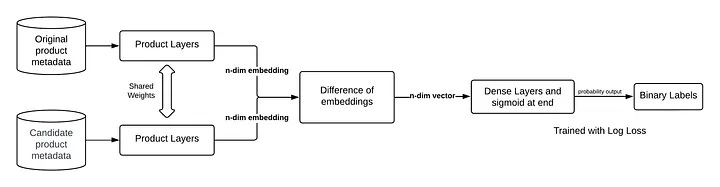
The evaluation is split into offline and online components:
Offline Evaluation: Metrics include validation loss (log-loss), Area-under-curve (AUC), Mean Reciprocal Rank (MRR), and Recall@k.
Online Evaluation: A/B tests monitor key metrics like replacement satisfaction and customer approval rates.
Part 2: Solving Head vs Tail Problem
The engagement model was developed to address the limitations of the deep learning model for frequently replaced ("head") products. While the Deep learning model generalizes well across a variety of products, it underperforms for head products that require a "memorization" component to prioritize top replacements.
This model uses customer engagement data to calculate historical approval rates and precompute scores for product pairs with high replacement frequencies. For example, in the honey-flavored cereal case, the engagement model prioritized substitutes most favored by customers, outperforming the DL model's generalization approach.
To achieve the best results, the engagement and DL models are combined in an ensemble approach. The engagement model assumes a higher weight as the number of replacement attempts increases, ensuring customer-preferred recommendations.
Hyperparameters are fine-tuned to optimize the offline metrics previously discussed in the ranking section.
Part 3: Optimizing for Retailer-Specific Inventory
The original Instacart replacement model used a (source_product_id, replacement_product_id) schema, applying a universal ranking system across all retailers. This approach overlooked retailer-specific inventory, leading to biased recommendations. Universally available products, like brand-name items, were prioritized over retailer-exclusive store brands, often causing customer dissatisfaction due to pricing mismatches.
To address this, the schema was updated to include retailer-specific data, transforming it into (retailer_id, source_product_id, replacement_product_id). The engagement model was also enhanced to calculate retailer-aware approval rates based on user interactions specific to each retailer.
This update improved the model's precision, making store-brand items more prominent in recommendations and better aligning replacements with customer preferences. Online A/B testing validated the change, showing statistically significant reductions in replacement issues and higher satisfaction rates for replacements fulfilled by shoppers.

Lessons Learned
Tailor Models to Specific Contexts: A one-size-fits-all approach is insufficient for complex systems. Retailer-aware schema and retailer-specific adjustments greatly enhance the relevance of recommendations.
Optimize for Customer Preferences: Understanding and accurately addressing nuanced customer preferences, such as brand, size, and dietary needs, is crucial for maintaining satisfaction.
Iterate with Feedback: Regular updates to the scoring pipeline and incorporating customer interactions (e.g., impressions and approval rates) ensure the system remains accurate and responsive.
Validate Through Testing: Offline metrics (e.g., AUC, MRR) and online A/B tests are key to validating model performance and ensuring improvements translate into customer satisfaction.
Leverage Retailer-Specific Data: Integrating retailer-specific inventory and engagement data eliminates biases, ensuring that recommendations are cost-effective and contextually relevant.
The Full Scoop
To learn more about the update, check the Instacart Blog post on this topic